如何评价 10 月 16 日发布的 Intel 14代酷睿处理器,这代性能提升如何,有哪些亮点和不足
这是一段我很早就想和大家说的话。
其实从2021年开始,我、Cloud和CHO就希望把严肃评测和商业评论带回知乎。我们已经烦透了每次发布会结束之后参数复读的内容形式,希望恢复评测行业严肃,量化和不带任何光谱情绪的内容主张。对于我们这个小团队的资源厚度和行业交际来说,在合规渠道提前获得产品是一件很容易的事情,无论是CPU、GPU、显卡、主板或者手机、路由器,我们都可以第一时间获得工程样品以及官方技术团队的全力支持,从技术手册到评测指引,甚至还会有一些商业化测试软件的CDKEY的支持。
我们希望让知乎在相关领域的权威性回到当年http://Gzeasy.com在全球评测行业的重要层面,为此我们不断做出努力。各位从历代酷睿处理器、Zen处理器、英伟达GPU和麒麟9000s的评测可以看出来,其实我们并不太在乎厂家的态度,我们也不会感受到厂家的压力,毕竟测试数据骗不了人的。
我们希望在知乎建立一锤定音式的严肃评测体系,脱离无机评测,立场决定舌头的低级趣味。
我十分喜爱十几年前的评测氛围:聊产品,聊行业,聊渠道,聊市场策略,但是就不聊光谱,不聊技术和商业以外的东西。我对那些东西没有兴趣,我是个坚定的全球化产业链支持者,所以我们会客观公正积极的面对每一款值得深入评论的产品和商业模式。
知乎也好,其他平台也好,这段时间无关技术,商业,品牌,销售的东西扯的太多了,这不应该,最后大家发现,除了口嗨之外,根本学不到任何东西。
让技术的归技术,商业的归商业,其他不要去扯,没有意义。
好了,进入第十四代酷睿系列处理器深度评测,附带ROG Z790 Dark Hero主板赏析。
本文接近三万字,文章较长/图表较多,建议使用PC或者平板浏览,完成阅读大概需要10分钟,也可以用目录跳转感兴趣的部分选择阅读。也欢迎在本文评论讨论和咨询,我会尽量应答。

本文主笔为cloudliu,我是第一编辑,欢迎关注Cloud !
cloud liuwww.zhihu.com/people/cloud-liu-46-69
同期CHO
的独立测试报告也完成,可以一并阅读
Edison Chen:能算是新品吗?酷睿 14 代测试简报34 赞同 · 6 评论文章
频率功耗和温度
14代的规格变化简单的说:14900K/14700K和14600K相比上一代全核心频率和Boost频率都提高了0.2GHz,再就14700K额外增加了4个E-Core(还有对应的缓存)。

我们可以发现13900K/14900K金属顶盖/还有背部电容排列也都完全一致。(最右是之前开盖的13900K)
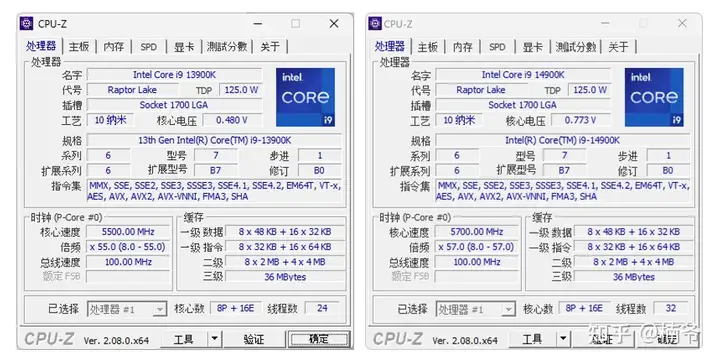
14代不仅架构(tick)/工艺(tock)和最大规模没有任何变化,从CPU-Z看甚至连步进都没变化,就说14代和13代是完全相同的Die,仅仅是频率有0.2GHz的提升,这可以说是历史上提升幅度最牙膏的升级。
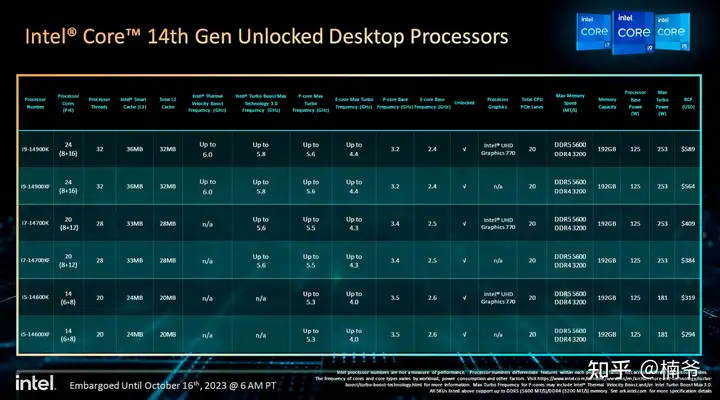
还是先说说频率,怎么正确理解intel处理器的频率。上图intel标注的什么最大睿频频率/TVB睿频频率/性能核最大加速频率实际都是没多大意义的。
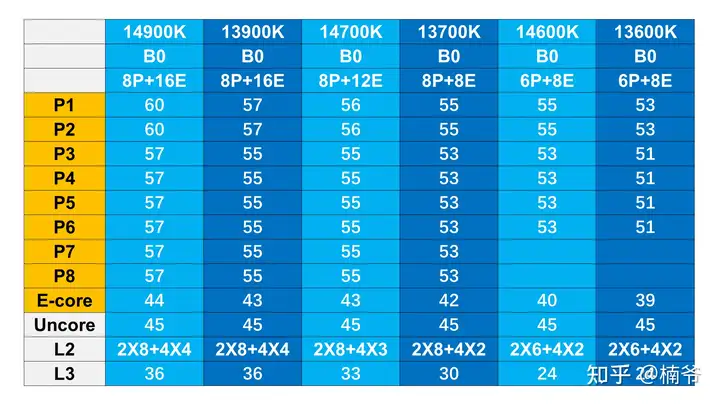
intel的频率控制机制十分简单,在没功耗墙和温度墙的情况,有负载核心数对应1个固定的频率,以13900K为例,1-2核心占用是5.7GHz,超过3个核心就最高运行在5.5GHz。
我之前在12代和13代的评测就多次强调,标的最高的睿频频率只是1-2线程负载的频率,这个频率最大作用就是让Cinebench和CPU-Z的单线程跑分好看而已,无论是日常使用还是游戏,都基本不可能只有1-2个核心负载,只要3个和以上核心有负载,即使是轻载,也只能跑最低全核频率,因此实际有意义的就是全核频率。 而AMD的频率控制机制会综合考虑电流和温度进行频率调度,7950X高负载生产力大概在5.1-5.2GHz,但游戏时候多线程轻载有负载的核心就可以动态的跑到5.5GHz+,因此我认为intel在频率控制机制上是落后AMD 5年的。
更具体一点说规格:14900K/14700K和14600K相比上一代全核心频率提高了0.2GHz,再就14700K额外增加了4个E-Core(还有对应的缓存)。除开P-Core频率,E-Core都分别向上拉了1个倍频,而14代K的Uncore和集显还是维持13代4.5GHz和UHD 770,也并无变化。

好,规格说完,其实性能也基本没上面悬念,基本可以收工了,但这样收尾就对不住人了,我要换些角度通过测试来解析14代,除了常规的性能测试,我也将更多的分析功耗/超频以及高频内存对于性能的影响,再说说选购和搭配建议,给与消费者最直接的选购指引。
测试平台

测试平台的设置原则是接近目标用户的实际使用情况,采用优化设置尽量发挥性能,但又不采用极端的设置而需要过高代价实现。

- 显卡我使用的是华硕TUF RTX 4090 GAMING O24G,不过我刷了ROG STRIX RTX 4090 GAMING O24G的BIOS,默认PL 500W,2610MHz的Boost Clock,要比公版高一些。
- 散热使用的Tt骁龙Pro 360 ARGB版,为了提升散热性能,我将风扇换成6把 3300 RPM雅浚H12PE夹汉堡(ROG主板BIOS得分200分+),并将主板的CPU温度墙改到115度,来保证400W的14900K满载不降频。
- 测试内存使用的影驰HOF OC Lab幻迹S D5-8000 16GB x 2内存,手动将参数缩到34-46-46-76.在没有特别说明的情况下降频到7600进行测试。
- ROG Z790 DARK HERO是使用的0504 BIOS,2264 ME。现在最新版的BIOS包含了ME部分,不再需要单独更新。
- AMD对比组这边使用的是7600X/7700X/7800X3D/7900X和7950X,主板使用的是华硕 TUF GAMING X670E-PLUS WIFI,1654 BIOS,虽然AGESA 1.0.0.7内存可以异步上到高频,单实际要8000频率效能才能和6400C28持平,中间频率实际效能是下降的 ,因此在没特别说明的情况下我还是使用6400 C28-38-38-58的内存设置进行测试。
- 可能有人会觉得AMD 6400 VS intel 7600不公平,但我这样的设置只是为了能够较好的发挥出平台性能而已,而且这个设置也比较接近目标用户的情况,并不极端,intel平台我也没去跑8xxx频率,7600频率稍微好点的Adie+4槽好一点的Z790/B760就可以达成,基本增加不了什么成本。(内存设置相关后面我会具体说明)
ROG Z790 DARK HERO硬件解析

14代intel甚至没有为了她准备新的芯片组,对应的芯片组依然为Z790/B760和H610。但板商也不可能什么都不做,因此还是采用了和Zen 3时候X570类似的策略,将Z790的主要产品重新Refresh了一次。我这次测试平台是由华硕借用的ROG Z790 DARK HERO。

虽然DARK HERO的细节处理有了一些变化,但整体还是延续HERO的风格,满满当当的供电加上硕大厚实的散热片可以给人充分的力量感和安定感。

Z790 DARK HERO的供电还是维持Z790 HERO的规格,供电部分采用20+1+2并向设计(CPU+集显+内存 红色标识)。加金属散热片的双8pin接口(蓝色),Procool金属散热片可以降低供电接口的温度。

MOSFET依然是Renesas ISL99390FRZR,单相可以承担90A电流。

内存虽然还是4 DIMM,但相比老版HERO进一步优化了布线,提升了内存在高频的稳定性。

IOCOVER的Polymo照明区域继续加大,屏占比更高,动效也更为华丽。

HERO的金属背板也继续沿用,这样可以保证PCB的结构强度避免变形变弯。

新一代的RTX 4090/4080都是三槽起步,一堆都是3.5甚至4槽,因此DARK HERO将拆分的PCIe 5.0 8x下移了一个槽位,而中间塞满了M.2。PCH和M.2的巨大整体散热片设计风格也进行了迭代更新,加装M.2的话需要整个取下。

DARK HERO同时也进一步调整了PCIe和M.2的部分策略,采用之前ROG STRIX Z90-E GAMING的方式,CPU下的22110的M.2是从PCIe 16x 5.0拆分出来的(CPU直连标识为紫色),也同下面拆分的PCIe 8x是共享带宽。如果你没有5.0 SSD的话,应该优先不使用这个M.2,使用这个M.2的话,不仅下面的PCIe 8x会被禁用,并且显卡接口会被降速到8X (但如果要用也不要纠结,我之前测试RTX 4090在PCIe 4.0 8X的性能损失也不到1%),虽然在8x即使是RTX 4090性能的影响也不到1%,但还应该尽量避免。而显卡16x下面的2280才是CPU直连的4X M.2。
下面的3个青色标识的M.2 2280就是PCH下的M.2 PCIe 4.0 4x,但遗憾的是最后个PCH下的PCIe从8x缩减到了4x,我现在自己用Z690 HERO,最后个8x拆分2个4x用转接卡接2个U.2还是很舒服的,对于我来说如果最后个PCIe是8x那这个布局就完美了。
DARK HERO的SATA从原有HERO的6个缩减到4个,去掉了第三方ASM1061扩展的2个SATA(现在应该没谁还需要4个以上的SATA了吧)。

DARK HERO后部接口没有使用USB 3.1 Type-C Gen 1这样摸不到头脑的此名称,而是直接标出的清晰明了的速率5G/10G:4个深蓝色是USB 5G/红的是USB 10G 4个Type-A一个Type-C,而青色标出的则是2个雷电4。WiFi天线口也不再使用之前的螺丝口,而是使用全新的卡口安装更简单。(特别是机箱放桌子下面的时候扭铜柱很痛苦)

以Dark Hero为代表,华硕新一代的Z790主板搭载的intel BE200无线网卡增加了WiFi 7的支持,最高可以提供5.8 Gbps的无线带宽。

不过目前国内工信部还没有开放6 GHz频段,导致WiFi 7的性能还不能完全发挥,但WiFi7中引入了MLO (Multi-Link Operation) 芯片级多路连接技术,带来更大的吞吐量,避免网速降低、卡顿、掉线等情况,同时还支持4096的QAM调制,相比WiFi 6有20%的还是有提升。此外DARK HERO主板自带的WiFi天线也重新设计,全新的天线不仅更容易布置,5 GHz/2.4 GHz频段的信号收发能力也有18%的提升。
VF电压频率曲线功耗和体质
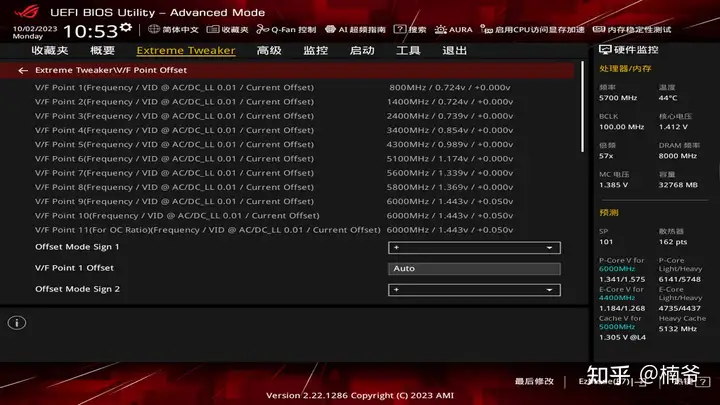
这里需要简单了解个概念:VF电压频率曲线:每个处理器有个对应的默认VF电压频率曲线,在每个频率对应一个电压值,在高频电压高保证稳定,而在低频就不需要那么高的电压,就用比较低的电压来降低功耗。
在一个频率点默认电压低的处理器往往体质更好,默认设置功耗更低,一般来说,超频到相同频率也仅需要更低的电压,或者相同电压可以达到更高的稳定频率,也就是说默认电压低的往往也是超频能力更好,ROG主板的SP体质分也是依据电压而来,电压越低分数越高。
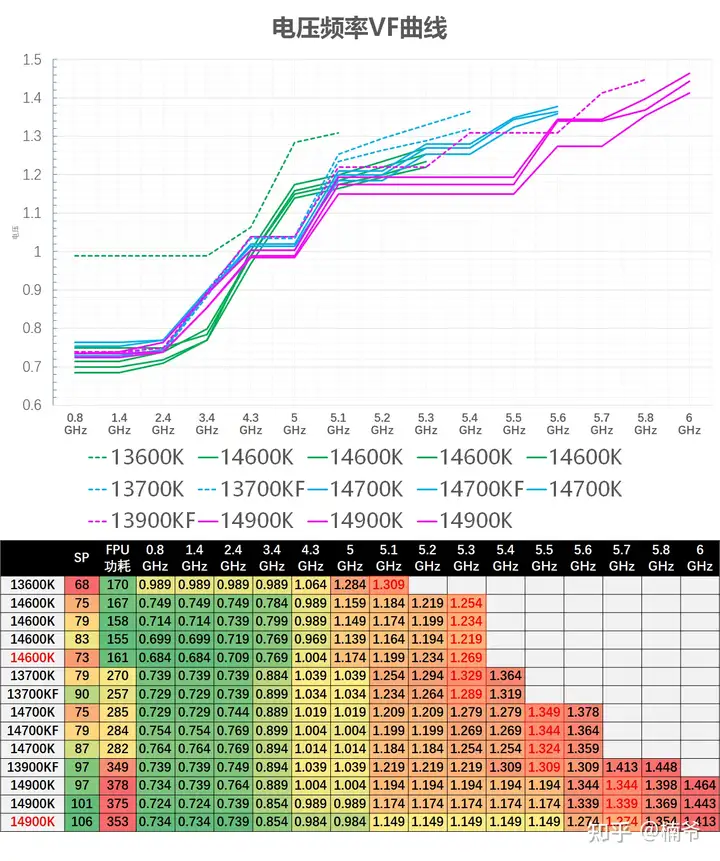
我们将我们手头的13/14代K处理器的电压频率曲线制作成图表。粉红色为i9,蓝色为i7,绿色为i5,实线为14代/虚线为13代:
整体而言虽然末端14代电压要比13代同级别要高,但同频14代的电压还是更低,体质还是更好。
波澜不惊的14600K
- 14600K体质相比13600K有大幅提升,甚至同频电压要低于14700K,当然我这个13600K也是太雷,之前还有个89 SP的13600KF可惜挂掉了。
- 我也试了下14代K处理器在B760上的情况,将79 SP默认FPU功耗149W的14600K在华硕TUF B760M PLUS WIFI(1402 BIOS 2264 ME)进行测试,默认FPU功耗180W,还是明显比Z790高,我又尝试手动降压OFFSET -0.15V,性能有小幅度的损失,R23大概从25300降低到24800,功耗下降到160W,使用104微码也一样,CEP应该还是触发了,但CEP策略应该是有调整。
等价交换的14700K
- 14700K虽然和13900K同频,但同频电压还是高于97 SP的13900K,功耗也从13700K的260-270增长到14700K的280+水平。但我手工降压SVID到1.18V(或者SVID OFFSET -0.08到-0.1V 和体质相关可能有所不同,再继续降压到1.16V就不能通过YC测试),满载功耗可以控制在230W左右,顶级双塔风冷应该勉强压得住。'
继续爆炸的14900K
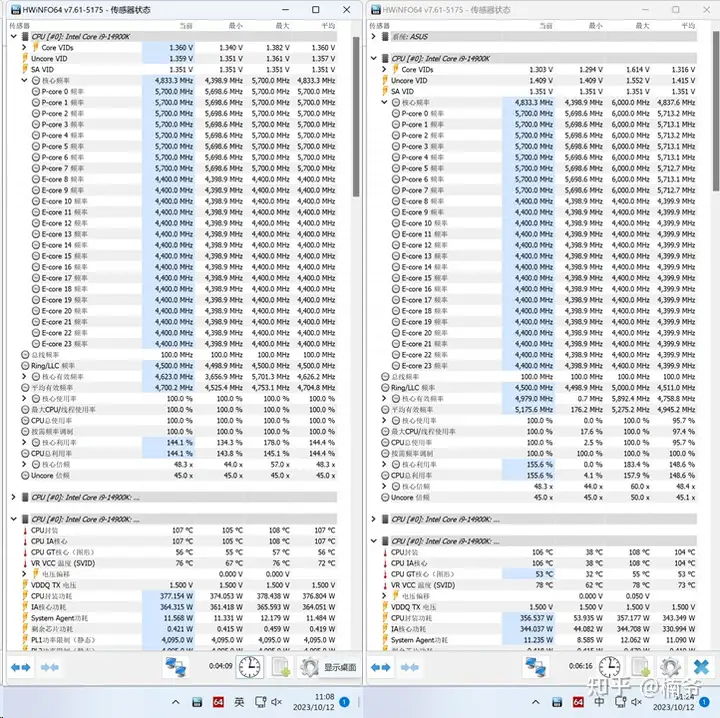
- 14900K/KF我手头3颗依据体质的不同,AIDA64 FPU满载功耗大概在353-378W范围,差的功耗相比13900K的350W区间再高20-30W,如果是PRIME 95/YC之类负载更高的测试,满载峰值功耗会到380-400W水平。但好的一颗5.7GHz电压还比13900K 5.5GHz电压低,满载功耗相差也不大,都在350W水平。
- 我故意挑了体质最差的97 SP的14900K进行降压测试,在SVID电压1.28V或者OFFSET -0.05V可以通过YC/P95稳定性测试(传感器读数为1.3V),AIDA64的FPU功耗也从380W下降到了350W,但350W的功耗依然超过了AIO这样的通常散热手段极限散热能力。
- 而体质好那颗降压到SVID 1.2V可以过YC,而FPU功耗就在300W以内,类似龙王3这样的高端的360 AIO就可以压在100度以内。
- Zen 4由于5nm的工艺优势,在满载功耗优势明显,但待机和轻载(典型的游戏场景),14代反而功耗更低,这应该和Zen 4的cIOD和IF总线功耗相关。
体质和玄学
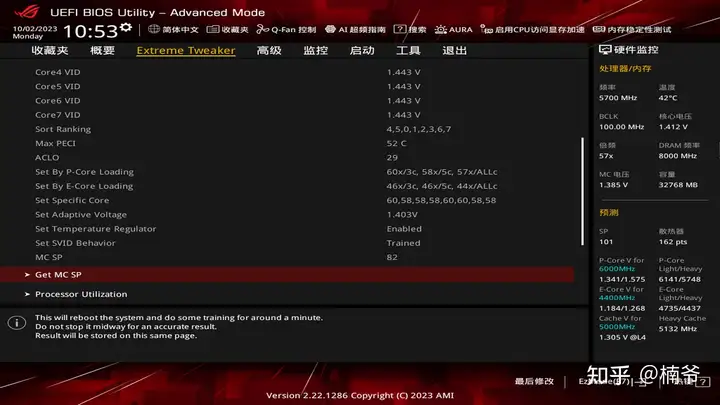
我用Z790 DARK HERO查看了下14代处理器的SP得分做了下统计,整理了下表:
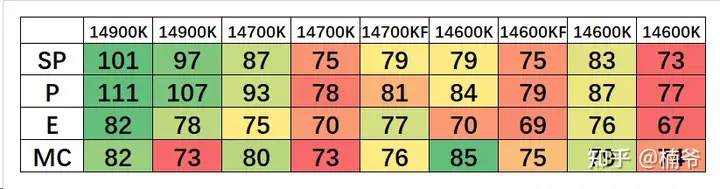
需要注意的是ROG STRIX可以查看核心的SP分数,而HERO以上的纯血ROG才能在AI Features下面GET MC SP看内存控制器得分,不同型号的主板/BIOS版本的SP分数也可能存在一些差别,MC分甚至多次GET也会不一样。我对了DARK HERO和我稍早测试用的APEX,SP分数和VF曲线是一致的。
处理器的SP分数主要是看VF曲线的电压,但不同型号也并不合适直接比较,看看上面的VF部分就可以明白。而MC得分部分就进入玄学领域,分数的低的也可能吃MC电压可以意外高频,但高分的一般都不会差,比如这颗MC 82的14900K在APEX上可以稳定8400,但具体是什么门道还是比较玄学的,估计只有写这算法的Shamino自己清楚。
14代MC部分给我感觉虽然头部也没比13代更好,但体质收束范围更小,下限更高,总不会碰到某人91 SP 67 MC的13900K惊天大雷,上个G.skill Mdie 24Gx2 7200 XMP默认都稳定不了,还需要手动加SA电压,可说是闻所未闻……
用ROG信仰全家桶,把我的DIY青春唱完152 赞同 · 49 评论文章
超频新思路 手工ABT 6 GHz打游戏
前面就说了,14900K默认5.7 GHz FPU 380W通常的散热手段就压不住,这样似乎就没超频的空间了?
这个问题我们首先我们要搞清楚自己超频的目的,是想要更高的全核心生产力性能,还是要更高的游戏性能?如果你和我一样,只是想要提高日常和游戏性能的话,则可以尝试下ABT的思路:
ABT的全称是Adaptive Boost Technology,自适应睿频技术,系统会依据处理器的温度/功耗/电流来动态调节。既然高负载全核心功耗温度压不住,那我还是跑默认,我追求的是在日常或者游戏这样的中轻载环境实现更高的全核心频率。 我故意选择SP 97 14900K大雷为例,以6GHz全核心打游戏为目标进行设置。
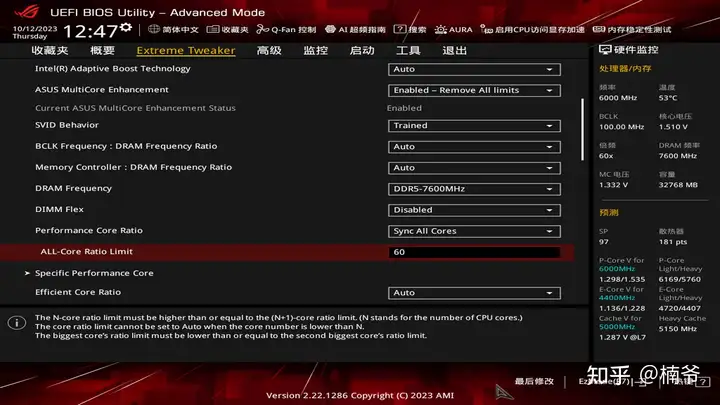
首先在BIOS设置P-Core 60倍频,E-Core我觉得无所谓,跑默认就可以。同时将SVID Behavior设置为Trained,这样系统可以依据训练结果进行SVID电压智能调整。
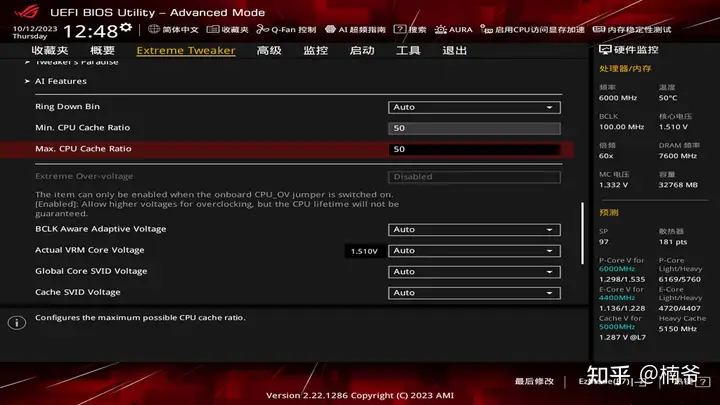
Uncore我设置50定频,其实这部分也可以在ABT里使用Cache Dynamic OC Switcher依据电流和核心负载进行动态调节,设置的更高一点。
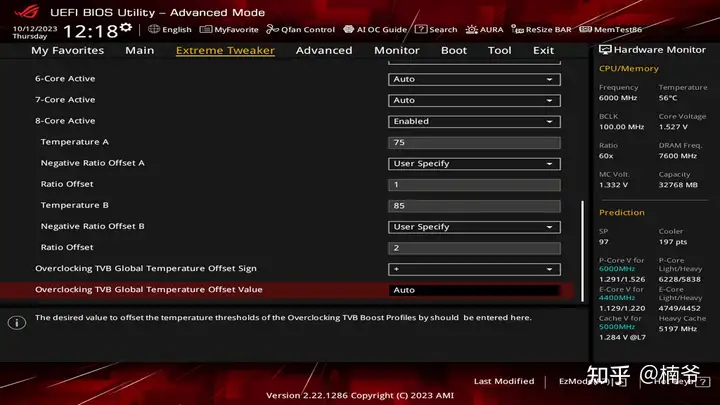
进入ABT的设置菜单,在这里我们可以设定ABT的策略:温度超过75度,倍频-1,跑5.9 GHz,超过85度,倍频再-2,跑5.7 GHz的默认频率,需要注意的是这个温度不要设置过于贪心,玩游戏可以温度到不了就好。其实我觉得TVB用温度可能有响应滞后的情况,特别是在用户散热很强的情况下,后续再加用功耗或者电流触发更好。
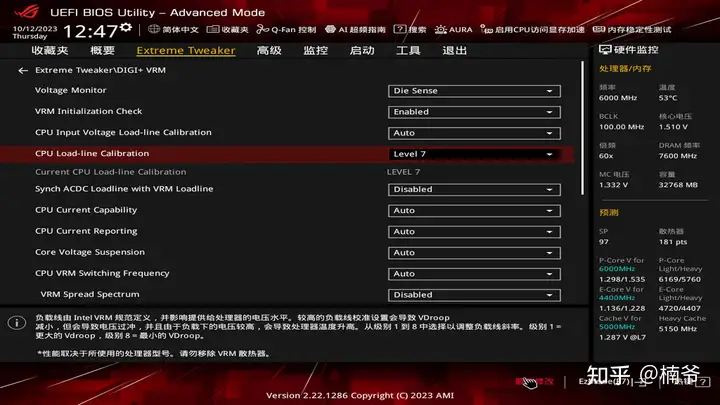
在在DIGI+ VRM里将防掉压设置在LV6或者LV7,其实这样设置电压基本就可以稳定了。
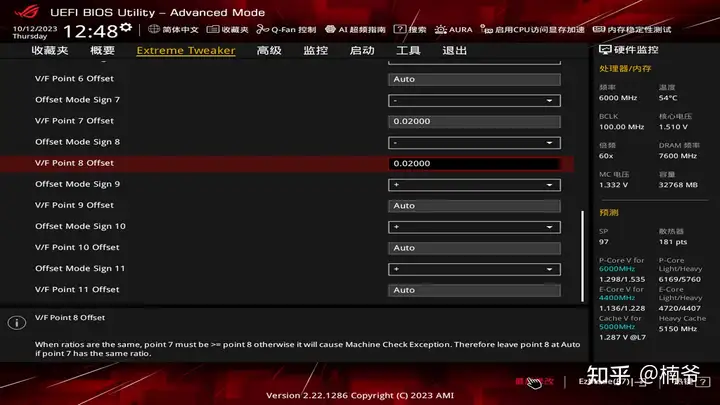
但这样在满载电压还是偏高,导致功耗和温度高,因此我这里没有定压或者使用全局的Offset,而是使用上面的VF曲线调整,VF7对应是5.6-5.7GHz全核心满载频率,我-0.02V来降低功耗,这样可以在1.3V 350W稳定跑在5.7 GHz。而VF9-11对应的是6 GHz电压,可以保持默认,如果不太稳定也可以正向加一点电压。这可以用7Zip benchmark或者游戏进行验证,再做手工微调。

这样设置在游戏的时候就基本可以跑在6 GHz,获得极致的游戏性能,而高负载就跑默认的5.7 GHz的默认全核频率,这样功耗温度不至于太爆炸。 但缺点是在日常/游戏跑6 GHz电压高,温度会有点偏高(上图玩2077功耗也有200W+)。后面的游戏性能测试部分我也会加入6 GHz 14900K+DDR5 8000的对比测试。
当然上面只是我尝试的一个思路,每个人的CPU体质也各有不同,也许各位有更好的超频玩法也欢迎在评论区分享。
内存频率和性能

这次测试内存我们使用的HOF OC Lab幻迹S D5-8000 16GB x 2内存,其采用Adie特挑颗粒,默认38-50-50-128 1.5V。
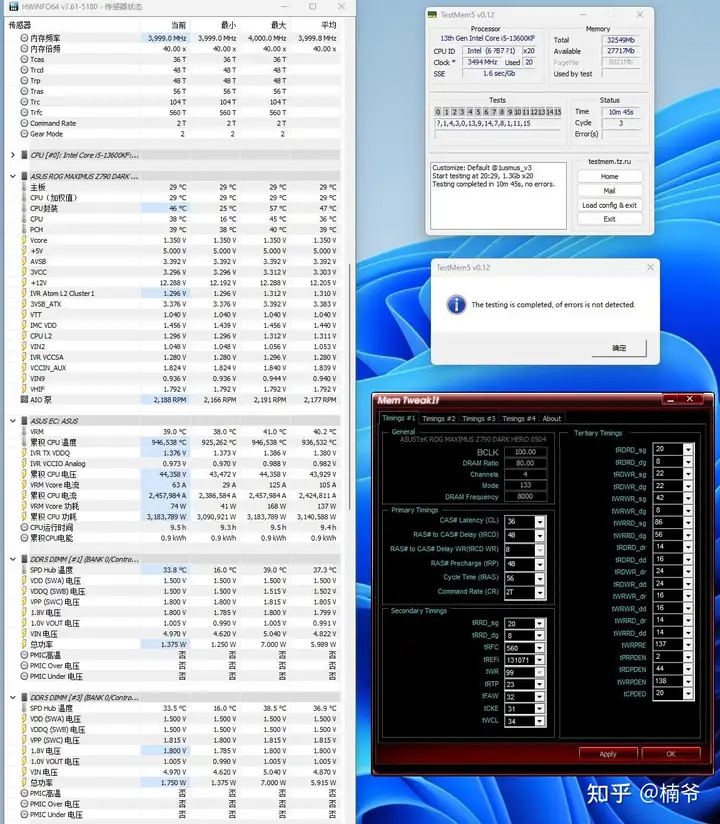
在第一代Z790,虽然APEX或者Z790i这样的2DIMM型号可以轻易跑到DDR5 8000,并且对CPU的内存控制器体质基本也没什么要求,但8000频率对于4 DIMM型号基本就几乎是不可能的。而HOF OCLAB DDR5 8000 16GB X 2可以Z790 DARK HERO上稳定的跑在8000频率 36-48-48-56 (具体设置为 VDD/VDDQ 默认1.5V SA 1.3V IVR 1,375V MCV 1.475V tREFI手工改131071 tRFC=560),并且通过TM5的1usmus稳定性测试。
如果你对tRFC/tREFI这些参数不太清楚,我在这里也做下简单说明:
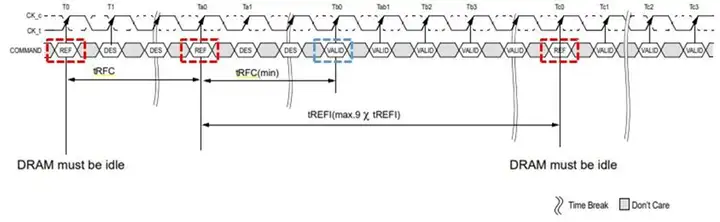
tRFC是内存存储单元的刷新时间 Refresh Cycle Time,在刷新期间内存不能进行其他操作,而tREFI是DRAM Refresh Intervals,内存刷新的间隔周期,多长时间刷新一次。
打个比方,就好比一个工人干活,tRFC就是干活累了休息的时间,而tREFI就是干多长时间的活就休息一次。对于资本家而言,自然希望内存休息时间短,休息的间隔时间长,这样才有更好的性能。
但内存和人一样,如果长时间不好好休息,就会觉得累(温度高),从而影响稳定性,因此如果要压榨这两个小参数就需要控制内存温度。我将tRFC设置为520,tREFI设置为65535,不到20分钟就会报错,需要额外加内存风扇才能稳定跑完TM5。
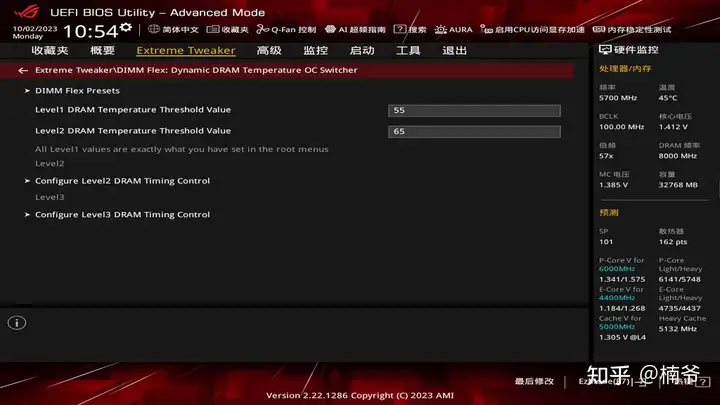
压低小参长时间高负载会使得内存温度升高,并且影响稳定性。但实际缩紧小参到C34 再设置tREFI=65535 打游戏稳定性还是没有什么问题。针对这种情况,DARK HERO增加了和缓存类似的OC Switcher功能,在额外的内存时序设置之外增加了2组额外的时序Profile,可以通过两级的温度墙设置三组配置:比如设置55度之下跑34-46-46-76 tRFC=520 tREFI=65535,而在55度之上跑默认的tREFI,而到65度以上再跑C36。这样的设置可以保证日常使用和游戏这样的轻载获得最佳的性能,而在生产力环境通过放松参数来提升系统稳定性。
我使用AIDA64 Extreme 6.92测试内存带宽和延迟。
- DDR4使用19-19-19-39参数
- 14900K DDR5平台默认使用34-46-46-76参数,优化额外设置tRFC=520 tREFI=65535
- 7950X平台默认DDR5使用34-46-46-76的统一参数
- 7950X平台默认DDR5 C28使用28-38-38-58的统一参数
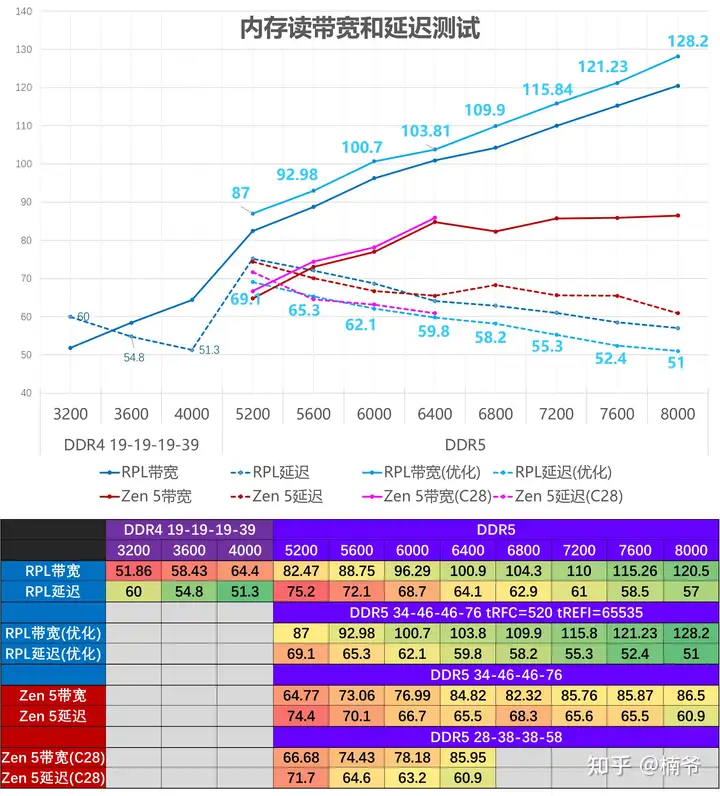
- 14900K在优化后,内存带宽有5GB/S的提升,而延迟也有5ns的降低,在8000 MHz频率带宽和延迟可以达到128GB/S和51 ns的水平。并且这还不是稳定的极限,如果继续压低其他小参,延迟可以控制在50ns以内,这个基本可以接近DDR4 4000的默认延迟水平(当然DDR4 4400极限压小参可以到40ns以内,这还是比不了)
- 后续在具体的应用和游戏测试中我们也将分析内存设置对于性能的影响,在没有说明的情况下,在没其他说明的情况下,后面我使用DDR5 7600 34-46-46-76 其他小参默认的设置进行其他测试,这个设置比较有代表性,一般的Adie+ROG Z790 4DIMM就可以达成。
- 7950X在6400和以下可以运行在Gear1模式,FCLK频率为内存频率的3/2,超过6400就只能运行在Gear2模式,FCLK频率为内存频率的1/3,并且高频还需要将参数放松到CL34,7600频率还是赶不上6400C28的效能。
- 7950x在6400频率将tREFI设置为65535,虽然带宽变化不大,但延迟可以大幅优化到55ns的水平,6400之下低频我就不测了,意义不大(其实是我懒)。
- Zen 4由于FCLK限制并不是每一个都可以运行在6400(特别是在经过烧U锁SOC电压之后),我手头7950X和7700X可以,7900X/7600X和7800X 3D只能6200。
- 另外我也测试了海力士3GB M-die的24GB DDR5,虽然其上高频能力要稍好于Adie,但在7400以上频率只能C36起步,即使使用和7200相同的C43主要参数设置,24GB的Mdie延迟相比16GB的Adie更高,因此24GB Mdie需要用频率来补效能。
理论和应用性能测试
SPEC CPU 2017理论性能测试
14900K架构没变化,仅仅是提升频率,跑底层架构意义不大,因此我就简单的跑了下SPEC CPU 2017的fpspeed和intspeed。测试过程将SMT超线程关闭进行测试,使用ubuntu 22.04系统+GCC 13.1编译器。
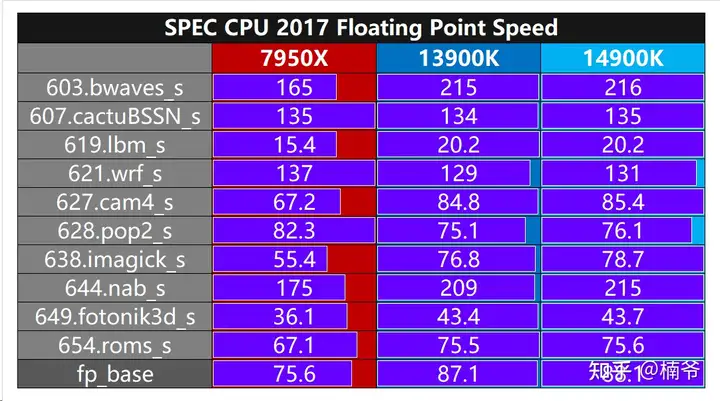
- 浮点部分14900K相比13900K整体性能 提升了1.1%。但我们将13900K DDR6 6400的成绩进行对比,从79提升到了87.1,反而提升了10.2%,就是说浮点部分DDR5 7600这样高频内存收益要大于13900K提升到14900K的收益。
- 浮点部分都是多线程,Zen 4仅仅在621 天气研究和预报模型/628 海洋模拟这2个部分占优,16个 E-core还是给RPL很大优势。
- 7950X在开启AVX-512后,fpspeed总分可以提高到79.1,大概有5%不到的提升。
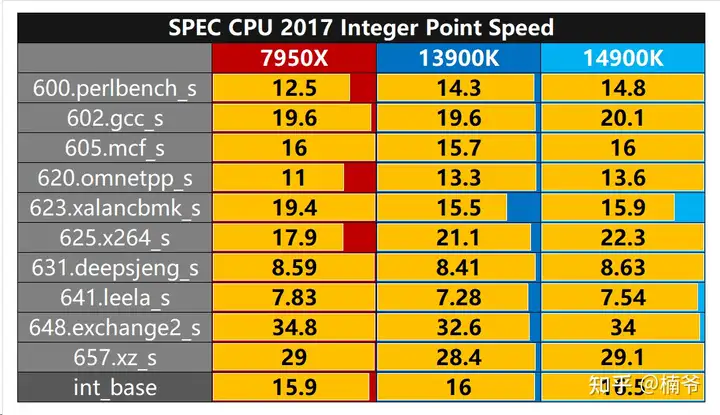
整数部分,除了最后的XZ的数据压缩部分,基本都是单线程,这部分14900K相比13900K提升了3.1%。但DDR5 6400到7600的收益就明显降低,仅仅提升了1.3%,并且这1.3%很大部分还是xz贡献。其实无论日常使用还是游戏,主要都是整数运算为主,浮点占比很低。
Zen 4在整数方面劣势较小,在623 XML到HTML文件转换/631 alpha-beta 树搜索和模式识别/641 蒙特卡罗模拟/648 数独谜题生成/657 数据压缩测试项目有少许优势。而且这还是在intel 13900K/14900K偷了3个倍频的情况下。
Cinebench 2024
新版CineBench 2024不再采用先前的标准渲染器,而是转向使用Maxon公司旗舰软件Cinema 4D的默认渲染引擎Redshift,并且新增了对GPU渲染的支持。我使用vTune初步分析2024相比R23,AVX/SSE的这样的Packed指令占比有所提高。
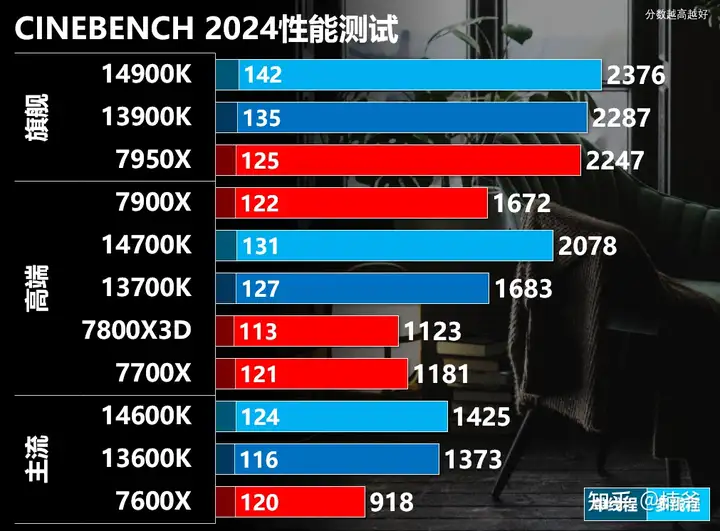
CineBench 2024整体负载并不算高,多线程就14900K 320W以下水平,再默认的100度温度墙的情况下,用个便宜的360水冷+3个3300 RPM暴力扇仅仅是个别核心掉频率,基本还是可以维持2300分,性能损失并不算大。
14700K相比13700K多了4个E-Core,多线程性能提升十分的明显。13600K/14600K同样得益于8个E-Core,也明显优胜于7600X和7800X,要知道8个E-Core所占核心面积仅仅比两个P-Core稍大,是提高多线程性能十分高效的方法。
从单线程测试成绩看,intel有一定优势,但i9偷了3个倍频,i7也偷了1个倍频,这个单线程性能是有水分的。
7ZIP性能测试
7ZIP测试主要是对内存延迟敏感,对内存/缓存带宽不敏感,而对于数据缓存容量/速度和TLB,还有乱序执行/分支预测敏感。这个测试不使用FPU和SEE,大部分代码是32位整型,少部分是64位整型。压缩测试有大量随机访问内存和缓存,执行时间的很大一部分CPU都在等待缓存或内存的数据。

- Zen 4的INT整型性能有优势,增加了50%的TLB。
- 此外分支预测失败率对于7ZIP性能影响也很大,13900K/14900K大概在10%,而7950X大概在6.35%,解压测试在分支预测错误后,流水线在下个时钟周期就无法正常工作,导致CPU资源就会利用不充分,但超线程可以改善CPU资源的利用率,因此超线程可以大幅提升解压缩性能,而GMT E-core又没超线程。利用率和效率就会存在问题。
- 7ZIP的由于是整型负载,功耗较低,Zen 4的稳定运行频率相比前面的渲染也更高,7950X可以运行在5.45/5.2GHz的频率,这进一步拉升了Zen 4的性能优势。
y-cruncher AVX性能测试
在AVX性能测试之前我用尽量浅显的语言简单介绍下AVX是什么,一般计算是标量操作,一个时钟周期只能进行一次计算,而以SIMD(Single Instruction Multiple Data 单指令流多数据流)方式可以以向量的方式,在一个时钟周期并行进行多个运算。
AVX (Advanced Vector Extensions 高级向量扩展)则是实现SIMD的路径。AVX-512相比通常的AVX2能够支持更大的寄存器位数,有更好的性能。AVX虽然由于并行度高,性能更好,但具体使用需要程序在编写的时候专门优化,并且需要在处理器内有相当大的专用电路来支持,但实际情况是,除了科学计算专业领域有较为广泛的支持,在通用的消费领域程序,除了视频编码/模拟器都很少提供对AVX-512的支持,AVX-512被不少人(特别是AFAN)说成是毫无用处,只能发热的电热丝。
intel在11代Rocket Lake提供了对AVX512的支持,在12代虽然大核心GDC支持,但小核心GMT并不支持,导致intel并未提供对AVX-512的官方支持。而在13代Raptor lake则彻底的放弃了对AVX-512的支持,但Zen 4却提供了对AVX-512的支持,这个时候不知道之前叫电热丝的AFAN是否还继续坚持之前的观点呢?
y-cruncher是一个多线程计算Pi的测试程序,可以充分利用AVX甚至AVX-512进行计算。最新的0.82版大幅提升了性能,同时负载和对于稳定性的要求也更高了,之前0.79可以通过的内存设置0.82却过不了。我们选择50亿位的多线程进行性能测试。

y-cruncher负载相当高,14900K最高功耗可以到400W,比AIDA 64 FPU要再高20多瓦。
在0.82相比之前的版本,AVX-512性能相比AVX2有更大幅度的提升,在7950X上AVX2性能提升了9%,而AVX-512则提升了30%,因此Zen 4借由版本升级获得更大幅度的性能提升(主要是优化的缓存内性能,超出缓存外的内存部分依然有很大瓶颈,因此提升内存性能可以立竿见影的提升性能)。7950x我跑Zen 2库完成时间为108秒,相比Zen 4库跑AVX-512慢了18%,也比14900K慢。
不过也不是所有软件都会针对Zen 4的AX-512进行优化,稍后我们再看看X265这样的实际应用环境的表现差别。
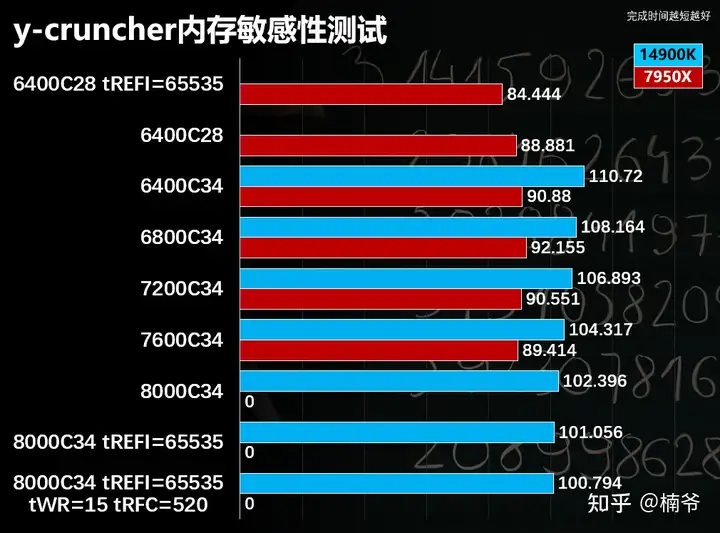
- y-cruncher对于内存带宽和延迟也都很敏感,14900K DDR5 8000优化小参后相比DDR5 6400快了接近10%。
- 7950X在6800以上的异步模式相比6400C28性能有一定下降,到7600频率拉回接近6400C28的性能,但也只是接近,8000频率无法稳定完成测试,跑8000的话效能应该可以有6400C28的水平,但需要B650i或者X670E Gene这样的2 DIMM的高端主板了,代价有点大,因此本次测试Zen 4平台在没特殊说明的情况下我还是使用DDR5 6400 28-38-38-58的设置进行。
- tREFI=65535可以比较明显的提升性能,特别是Zen 4平台,完成时间从默认的88.88秒提升到84.44秒。
X265编码性能测试
X265编码是重AVX的测试项目,这个测试基本是CPU最高负载的测试,同时我们使用X265考核处理器的极端条件的功耗和温度。 编码使用的视频源文件是ducks_take_off_2160p50.y4m,使用 slow 预设,以 28 恒定速率因子来压缩,码块树 CTU 数量为 64 个。对于Zen 4我分别使用AVX2和AVX-512指令集进行测试。使用的命令行分别如下:
x265.exe ducks_take_off_2160p50.y4m –preset slow –crf 28 -o duck.mp4 –ctu 64 –profile main10 x265.exe ducks_take_off_2160p50.y4m –preset slow –crf 28 -o duck.mp4 –ctu 64 –asm avx512 –profile main10
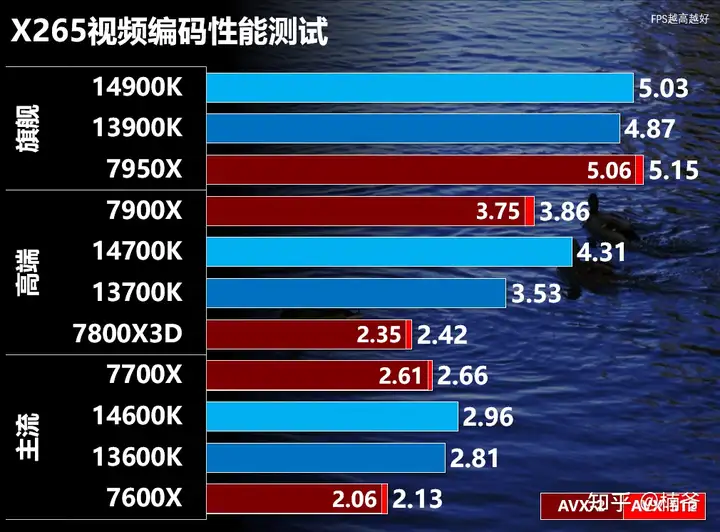
虽然这次内存设置更高,但x265所有处理器性能相比13代的首发测试有明显倒吸(还是在内存设置更高的情况下),我先怀疑是Windows更新的问题,但在ubuntu平台下跑也一样,那应该还是和BIOS/ME相关,估计又是修正什么漏洞闹的吧。
Zen 5的AVX-512相比AVX2大概有1-2%的性能提升,这个幅度明显是小于前面y-cruncher的结果,x265有段时间没更新了,其实我也考虑改用ffmpeg替代x265,但ffmpeg最近几年AMD平台的CPU占用率和性能都存在问题。
Office应用性能测试
应用性能测试我们们使用UL的Procyon进行测试,其特点是调用真实应用进行实际操作来测试硬件性能,这样更为贴近用户的真实使用情况。
办公室生产力基准测试是根据在办公室里典型一天的常见任务而设计的。该基准测试打开Excel 表格、PowerPoint 演示文稿、Word 文档和 Outlook 电子邮件。这些应用程序会同时运行,而焦点会从一个任务移到另一个任务。例如,该基准测试从 Excel 中复制一个图表并将其添加到 PowerPoint 幻灯片中。它从一个 Word 文档中获取文字并将其添加到另一个文档中。该基准测试着重于测量直接影响用户体验的性能方面,如提供流畅的互动和快速处理大型任务。
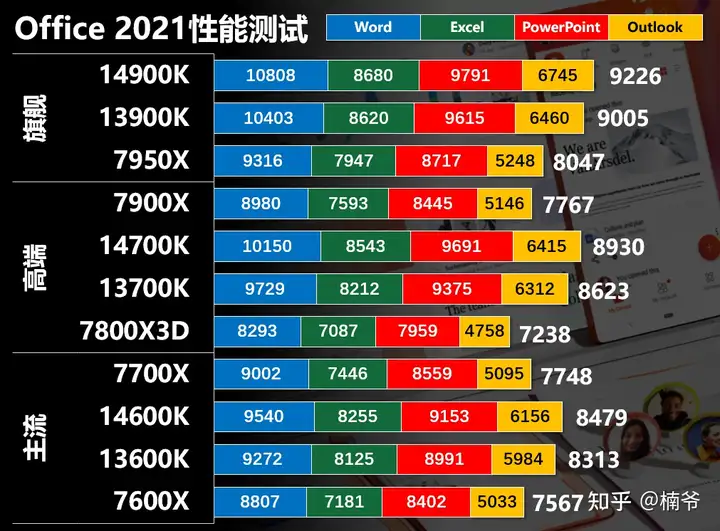
Office测试明显是频率敏感性,5.3GHz的14600K和13700K/5.5GHz的14700K和13900K性能十分接近。但Excel对于核心数量相对敏感,14700K相对13700K有比较明显的提升。Office性能intel还是有明显的优势,打工人想要干活快还是要选intel。
Adobe应用性能测试
UL Procyon 照片编辑基准测试在典型的照片编辑工作流程中使用 Adobe Lightroom Classic 和 Adobe Photoshop,其中包括图片修饰和批处理。UL Procyon 照片编辑基准测试首先将数字负片 (DNG) 图像文件导入 Adobe Lightroom Classic,然后应用各种预设。一些图片被裁剪、拉直和修改。在测试的第二部分中,将多个编辑和图层效果应用于 Adobe Photoshop 中的照片上。基准测试分数用来衡量电脑执行这些任务的速度。
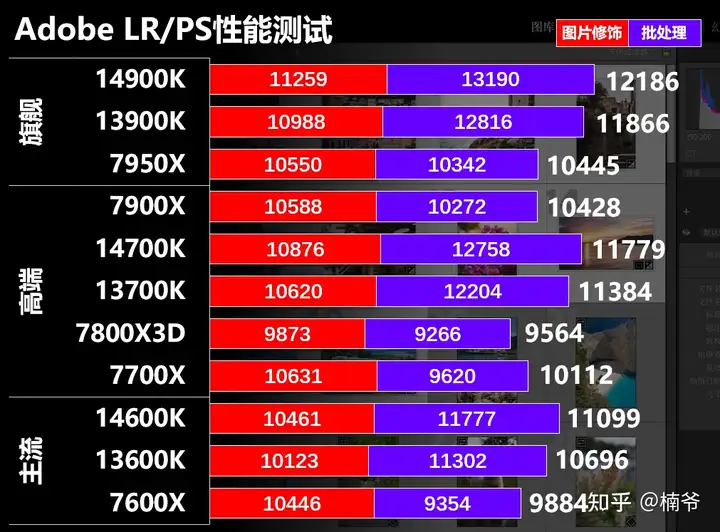
Adobe测试前面的图片修饰部分对于线程数并不敏感,除了7800X 3D偏慢,其他处理器的性能差距都不大,而批处理部分intel有明显优势,性能随着核心数量的增加有一定收益,但性能提升幅度并非随核心数量线性增加。
游戏性能测试
游戏性能测试之前,我需要再复习一次CPU瓶颈的两个概念:
- 第一是玩游戏CPU性能够不够用,不是看CPU吃满没,而是看GPU使用率,如果GPU没吃满那基本就是CPU瓶颈, GPU使用率越低,那就说明CPU瓶颈越大。
- 第二是GPU FPS和 CPU FPS,这是GPU和CPU能够支持的性能,实际游戏的FPS是由当前时刻的CPU FPS和GPU FPS的下限决定。
- 画面复杂的3A,特别是大型沙盘游戏会提高对于CPU的性能需求,但此时GPU的性能需求提升更大。
- 一般游戏的系统需求越低,GPU FPS越高,那游戏FPS的瓶颈就基本是偏向CPU FPS(特别是英雄联盟/CS这种帧数几百的电竞游戏),如果是性能需求极高的3A,性能瓶颈基本都在GPU FPS,特别是在画质拉满/分辨率拉高,再或者是显卡不太好的情况。
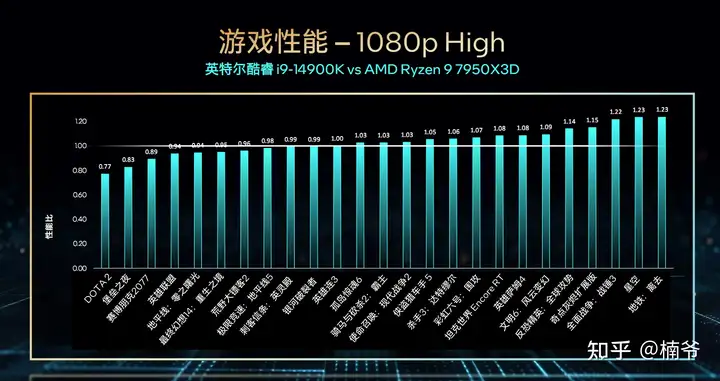
有些人测试CPU,会选择1080p这样的低分辨率/甚至低特效进行测试,虽然这样会突显CPU的性能差距,但同真实用户的实际应用情况是脱离的,因此我设置基本会选择尽量贴近玩家实际使用的设置,游戏从系统需求从低到高开始测试。
CS2游戏性能测试
我准备在9月28日开始测游戏,早上打开Steam的时候,库里的CSGO自己就开始更新,不由分说的变成了Counter Strike 2。之前的CSGO的Replay就不能使用了,为了测试我自己打Bot Dust 2一局,Record了个2回合的Demo用来测试(Dust 2图GPU负载较低,更多考研CPU性能),幸好控制台命令没有变化。我设置的是4K/2K/1080P分辨率,全特效, 4X MSAA 16X AF进行Timedemo。需要注意的是CS2默认fps_max是400,需要用控制台手工改大。
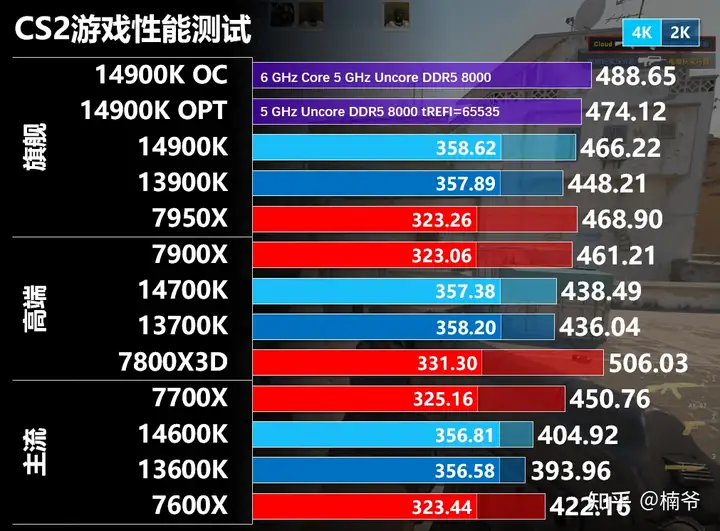
- RTX 4090在4K分辨率完全是GPU瓶颈,GPU占用率一直是100%,并且CS2对于多线程优化很好,可以吃满14900K 所有24个物理核心,但intel处理器都在350FPS,但AMD处理器基本都在32x FPS,就7800X3D快点到了330 FPS。
- 而在2K分辨率,GPU占用率在70%左右,完全是CPU瓶颈,性能开始分化。整体而言,在2K分辨率,Zen 4相比RPL有少许优势。特别是7800X3D,帧数超过500 FPS,性能优势十分明显。
- 14900K将内存频率拉升到8000 MHz/tREFI=65535,再超频到6 GHz,性能分别还可以有10 FPS的提升,但即使如此性能还是赶不上7800X 3D。
- 实际是不少班子玩游戏喜欢用1080p,甚至4:3的奇怪分辨率(比如1024x768),除了获得更高更稳定的FPS以外,还跟操作习惯有关系,一个固定的分辨率+FPS,对应固定的鼠标DPI和游戏内鼠标速度率,玩家的习惯惯性是很难改变的。但我测试了1080p分辨率,由于完全是CPU瓶颈,性能基本和1440p一样,我就不单独列出。

现在类似ROG Swift Pro PG248QP这样的电竞显示器刷新率都高达540 Hz,更到的帧率有利于提升CS2这样电竞游戏的表现,因此以500 FPS为目标并不是好高骛远。并且即使用户的显示器到不了那么高的刷新率,更高的FPS还是有利于提升操作响应。
英雄联盟
英雄联盟设置为4K MAX画质,使用游戏自带回放召唤师峡谷无限火力回放进行测试。英雄联盟GPU需求很低,是完全的CPU瓶颈,降低分辨率和特效也基本不会提升性能。
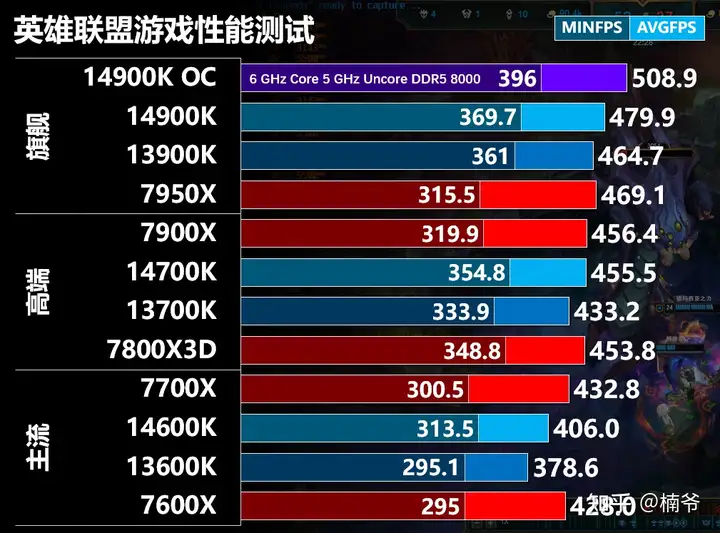
- 其实在测试12代ADL的时候,12代还是大幅落后Zen 3的,但到13代由于缓存系统的改进,RPL和Zen 4性能在一个个水平,14600K差于7600X,但14700K/14900K都小幅领先,并且在最低帧的稳定性上更好。
- 7800 X3D的情况也差不多,平均FPS和其他Zen 4持平,但最低帧数比较好。这样的情况,应该是英雄联盟游戏比较简单,32MB L3就可以满足需求,X3D多出来的L3边际效应就比较明显。
- 英雄联盟大概只用的上4个线程,14700K但更多核心带来更大的L3缓存还是有明显的收益,频率的影响就比较小。
绝地求生
绝地求生我们依然使用DX11增强路径,画面我们设置成4K分辨率,纹理、视野距离和抗锯齿最高,其他最低,这样的设置能够在画质和性能之间能够较好的平衡,同时画面也较为干净方便索敌。测试我们使用沙漠图游戏回放,使用CapFrameX记录游戏20-23分的180秒包含中远距离战斗的平均FPS。
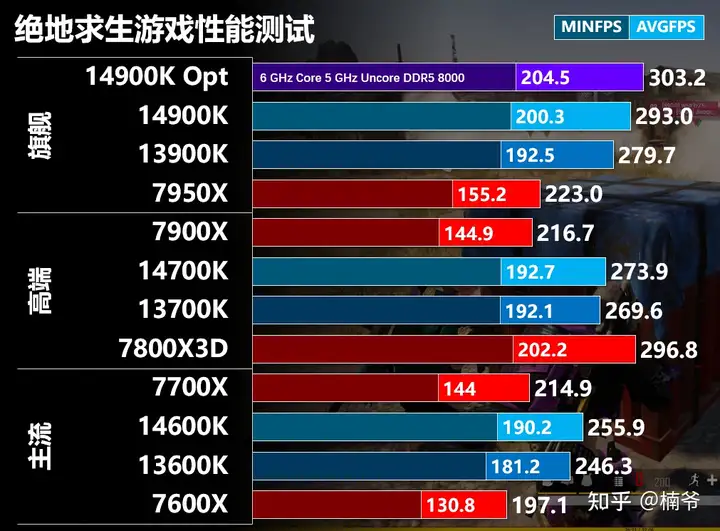
intel 13/14代是明显领先于7800X3D之外的Zen 4,而7800X 3D则比14900K还快10%。
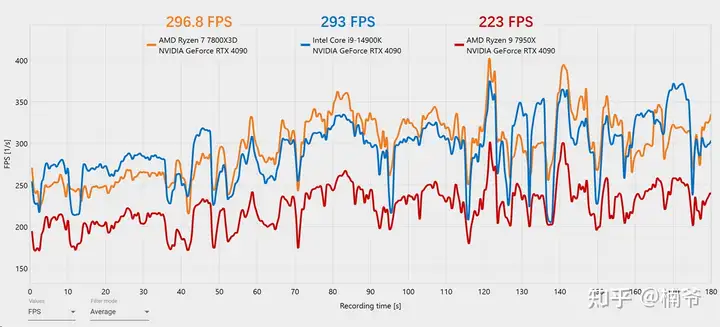
再分析具体FPS,7800X 3D相比14900K不仅FPS更高,而且突然画面变化导致的帧数波谷部分,7800X 3D的波谷也更浅,低帧的稳定性更好。另外Zen 4如果关闭SMT的话,在PUBG里大概可以获得额外10%的性能提升,7800X 3D关闭SMT可以到334 FPS。
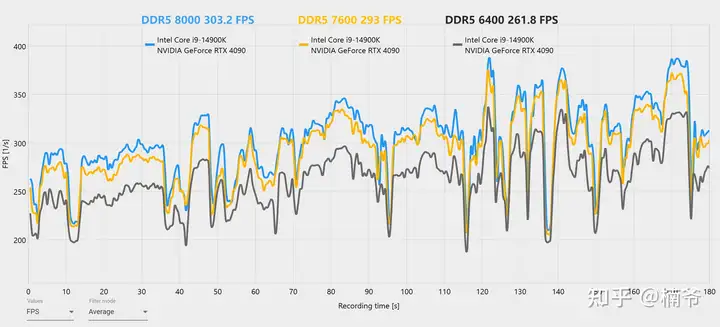
另外内存的设置对于PUBG也有很大的影响,我这里分别测试了6400C34/7600C34和8000C34 tREFI=65535的性能,分别为261.8 FPS/293 FPS/303 FPS。DDR5 7600相比6400快了12%,再次提高到8000C34 tREFI=65535,性能又提高了3%,tREFI对于性能的影响还是比较明显。在你显卡性能相对溢出的情况下,提升内存频率到8000并压低参数,在PUBG中还是可以获得比较大的性能提升收益。在内存8000压小参的情况下再超频6 GHz,平均FPS可以超过300 FPS,终于艰难的反超默认开启SMT的7800 X3D。其实对于游戏,单纯的提升频率的效果还不如收紧tREFI这样的小参,对于性能增益更为明显。
古墓丽影暗影
古墓丽影暗影虽然现在看有一点点老,但其提供了十分详尽的CPU性能分析,并且GPU性能需求现在看比较低,合适分析CPU性能对于3A游戏的性能影响。我这里使用4K DLSS性能/MAX设置使用游戏自带Benchmark进行测试。本次3A都使用DLSS性能模式,因为这样可以拉升性能加大CPU性能的影响,而且开启性能模式也基本才能满足现在高端主流的4K160显示器的性能需求。
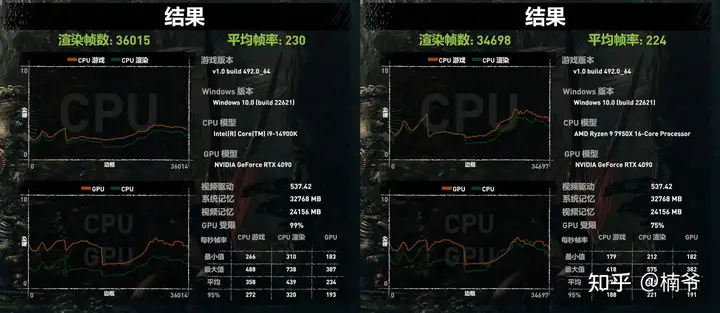
上面是14900K和7950X的测试结果:游戏测试在中段以后有段画面比较简单,GPU FPS大幅提升,7950X这个时候GPU FPS>CPU FPS,25% CPU性能成为瓶颈。而14900K全程CPU FPS>GPU FPS,99%是GPU瓶颈,其他13/14代K处理器也都差不多,都完全是GPU瓶颈,性能也基本一样。
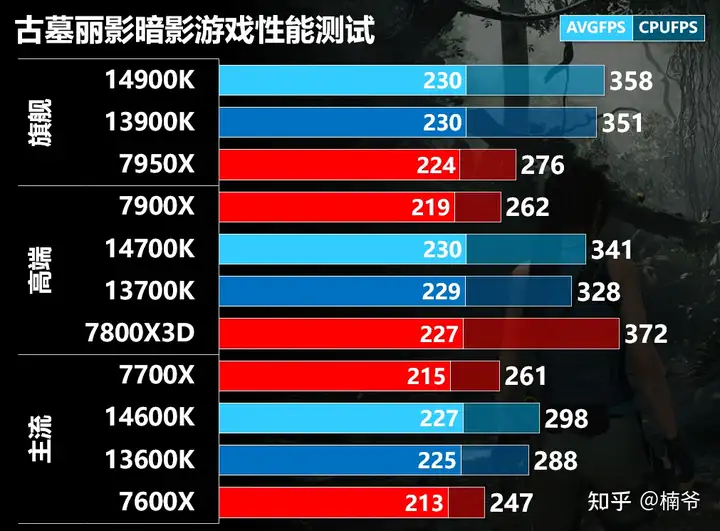
7800X3D和intel 13/14代K处理器都没瓶颈,性能也基本都是顶头的230 FPS。但具体CPU FPS还是有差别。7800X3D CPU FPS力压14900K,但由于是GPU瓶颈,这样的CPU性能优势却无法转化为实际的游戏性能优势。
除开7800X 3D,其他的Zen 4处理器相比intel 13/14代K处理器还是有5-10FPS的性能差距。
极限竞速地平线5
极限竞速地平线5在今年更新增加了对光线追踪的支持,这样压低了GPU FPS,使得CPU FPS的瓶颈减小。我测试使用4K DLSS性能 MAX设置使用游戏自带Benchmark进行测试。
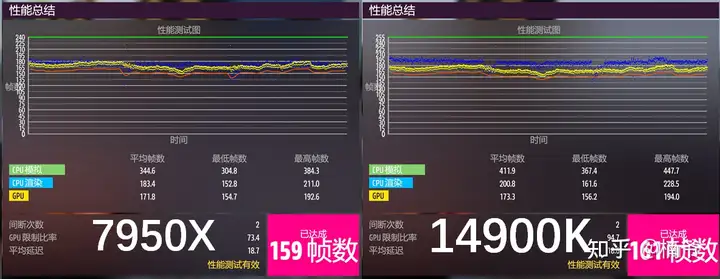
这个结果图黄线是GPU FPS,蓝色是CPU FPS,橙色是游戏实际的FPS,左边7950X 蓝色的CPU FPS和黄色的GPU FPS基本都在一个水平,有73.4%是GPU瓶颈,那就是说有22.6%是CPU瓶颈,并且中段由于CPU FPS有2次大深度下落导致的有两次明显卡顿.而右边的14900K虽然161 FPS仅比7950X高2 FPS,但CPU FPS要高9.5%,除了两处深度较浅的CPU性能下跌,整体蓝色的CPU FPS曲线都要明显高于黄色的GPU FPS曲线,仅有5.3%是CPU瓶颈,整体FPS曲线更为平滑,游戏体验也自然更好。
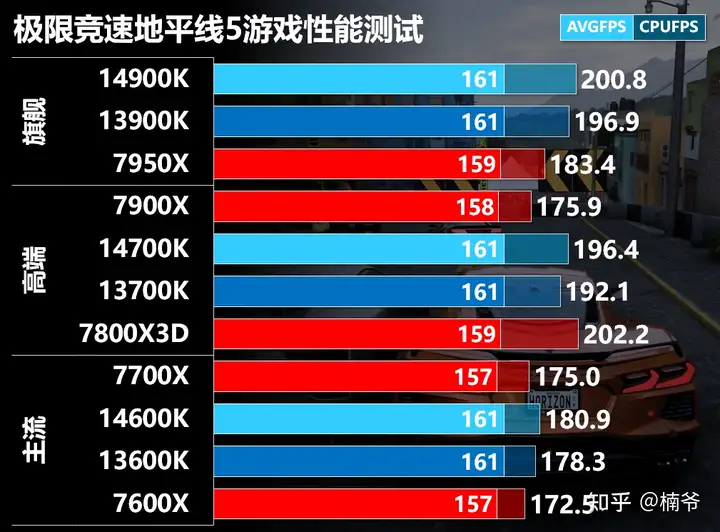
CPU FPS方面7800X 3D十分接近于14900K,也小幅领先13900K/14700K,但这主要都是GPU瓶颈了,最快的161FPS相比最慢的7600X也就快4帧。
赛博朋克2077
赛博朋克2077在上月推出了往日之影资料片和2.0版本补丁,在上一版本路径追踪的基础上增加了DLSS 3.5的支持,DLSS 3.5主要是增加了光线重构功能,在提升画质的同时又小幅提升了性能。·另外是优化了核心调配,提升了CPU的利用率,特别是优化了AMD处理器的性能。我设置为全特效(包括路径追踪),开启DLSS性能和光线重构,测试了2K和4K分辨率下的性能。

赛博朋克2077 2.0在14900K上不仅吃完了8个P-Core和16个E-Core,甚至还吃了4个P-Core的超线程,对于多线程的利用十分的充分。但在7950X上却调用的是第一个CCD和第一个CCD的超线程,而基本没用第二个CCD,这样的策略估计是AMD觉得跨核心调度的代价更高。
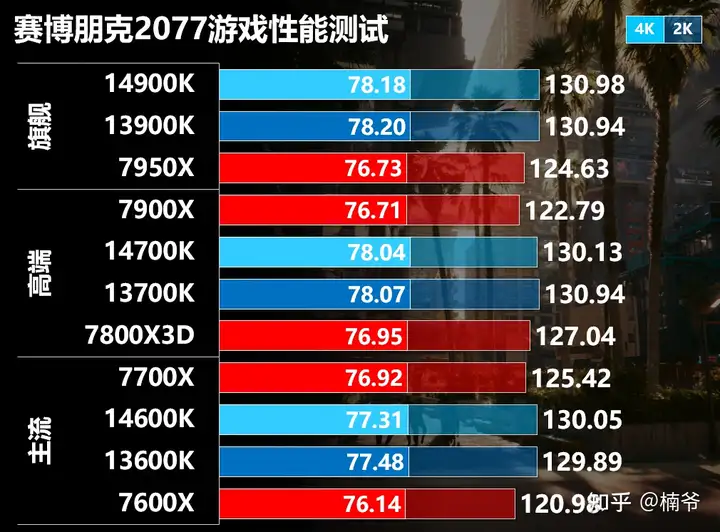
在拉满特效开启路径追踪的情况下,即使是RTX 4090在2K DLSS性能模式也是完全的GPU瓶颈,要知道2K DLSS性能的渲染分辨率实际只有720p,因此可以说是众生平等,但整体RPL相比Zen 4还是有1FPS的性能优势,而在2K分辨率性能差距拉开到5FPS。在2K分辨率7800X 3D相比其他Zen 4处理器还是有少许优势。
虽然赛博朋克2077可以吃满24个以上的线程,但13600K/14600K在拉满的画质下也没明显的性能劣势,不过就6个核心的7600X在2K分辨率大概还是慢了10 FPS,核心数还是太少了。
游戏性能小结
- 游戏FPS是取决于GPU FPS和CPU FPS的下限。
- 玩显卡要求低的游戏/更换更好的显卡/降低分辨率和特效可以提升GPU FPS,在GPU FPS比CPU FPS高的时候就会出现CPU瓶颈。
- 而使用不太好的显卡玩画面华丽的3A游戏/提升分辨率和特效,这样都会降低GPU FPS,使得GPU FPS不会被CPU限制。
- 一般来说帧数超过200 FPS,CPU瓶颈在才会比较明显,FPS越高这个问题往往会更为显著,特别是英雄联盟/CS2/PUBG这样的电竞游戏。
- 具体举例,如果是13400+RTX 4060 Ti 2K分辨率这样的配置,玩LOL是CPU瓶颈,但玩CS2/PUBG就开始是GPU瓶颈,而类似赛博朋克2077这样3A则完全是GPU瓶颈。
Z790 PCIe 5.0磁盘性能测试

我稍早用华硕PRIME Z790-P+13900K+HYPER M.2卡进行过群联E26主控的美商海盗船MP700的测试,intel平台的磁盘性能是明显优于AMD Zen 5平台的,甚至Z790 跑在PCIe 4.0的整体性能都要优于Zen 5的PCIe 5.0。E26的性能相比现在P44 Pro/SN850X这些4.0旗舰还是有明显优势,但问题是现在E26价格在这些4.0旗舰价格两倍以上,还是太不划算了。
PCIe 5.0 M.2 intel这边要等到ARROW-LAKE-S+Z890才会支持,那个时候PCIe 5.0的消费级需求量才会起来,三星/西数/海力士这样的原厂届时才会入局,价格也才会下来,现在消费级玩5.0 SSD还是太早了点。
具体的测试全文可以参看:
PCIe 5.0 固态硬盘来了,能起到哪些作用?3 赞同 · 0 评论回答
选购建议
处理器选择建议
14700K除了提高0.2 GHz频率还增加了4个E-Core,使得其是这次升级幅度相对最大型号,同时也是用风冷压得住的最高规格处理器。
而14600K和14900K仅仅是提高了0.2GHz频率,不过14代整体体质更好,可以稳定的频率更高,并且同频的电压功耗更低,你可以将这两个型号当作13代的特挑大雕。
虽然这一代的性能提升幅度很小,十分牙膏,如果不是刚需,我还是更为建议等待明年的Zen 5或者ARROW LAKE-S处理器。但如果你有刚需必须购买,我建议还是购买14代处理器,14代处理器整体相比竞品Zen 4还是有更好的生产力性能和游戏性能。
7800X 3D凭借超大的L3缓存容量,使得其相对其他Zen 4有不错的游戏性能,甚至在CS2/PUBG这些电竞游戏中相对14900K也都有一定优势,但其过低的频率和核心数量使得其在生产力和日常性能比较差,再加上其24xx元比7900X还贵的售价,使得其更像是一个十分偏执的小众产品,并不合适所有人,而7900X3D和7950X3D又实在没什么性价比。
另外你如果还是在使用12代处理器,或者是使用13代比较低规格的型号,再或是对处理器的体质不满意,升级14代也是不错的选择,原有平台基本可以不动,卖掉12/13代处理器也能有比较高的残值。
当然,14代京东自营首发价格相比现在13代售价是偏高的,并做不了平替。但从渠道价格看,我相信10多天后的双11就应该会和现在13代的价格持平,而13代也暂时不会退市,价格会略微向下调整。
有些人是十分不喜欢大小核的,我在之前12代和13代的评测就多次说过,其实intel大小核调度的策略十分简单粗暴,前台任务以此优先使用P-Core/E-Core,最后使用P-Core的超线程,后台任务则优先使用E-Core。基本可以做到硬件黑箱化,并不需要除开系统以外的程序进行特别优化,我自己使用12代/13代几年也没碰见什么问题。当然也有这样的情况下,比如在后台跑限定核心使用数量的虚拟机/模拟器,你希望他跑在P-Core,但他跑在E-Core,但我觉得这样的情况比较极端了,一般后台又不重载的程序都是性能不敏感,这样的情况就需要自己指定核心绑定了。
我甚至觉得双CCD型号的7900X/7950X的核心调度问题更大,我测试过程发现游戏使用核心超过单CCD数量的时候,程序往往是优先使用第一个CCD的超线程,当然使用第二个CCD的核心需要通过IF跨die,存在缓存一致性的问题,实现代价甚至会更大,因此现在游戏基本只会用第一个CCD的8个核心。
主板选择建议
我们本次测试的ROG Z790 DARK HERO超高的供电规格可以更好的应对14900K这样400W级的功耗,重新优化的内存布线也可以提供8000 MHz级别的高频内存支持能力,支援的WiFi 7的BE200+全新设计的天线能够提供更好的无线连接能力。BIOS功能也进一步完善,创新的加入了内存OC切换器和一系列的新功能,使得主板有更好的可玩性,能够同时兼顾巅峰性能和绝佳的稳定性。
当然,如果你预算稍低,或者准备装一台白色主题的整机,也可以考虑ROG STRIX Z790-A GAMING WIFI S,虽然其在规格上有一定的缩减(如供电为16+1 70A,WIFi 7芯片为BE202),但也应该可以满足不太需要折腾玩家的需要。
对于我吸引力最大的当然是Z790 APEX Encore,APEX虽然是定位极限超频,但按我之前玩的经验,APEX反而是最省心的选择,特别是内存超频方面。这代Encore加大了马甲覆盖面积,卖相更好,PCIe布局也更合理,还有额外的内存散热风扇,可以说是最接近完美的Z790主板。
不同档次的主板主要差别在供电规格/扩展性和内存支持频率。具体可以看看下面的选购指南,虽然是针对13代处理器和第一代Z790主板,但现在仍然适用:
内存选择建议
高频低参内存对于PUBG/CS2这样的电竞游戏还是有很大的收益,对于追求性能的玩家而言还是很有必要的。
如果你使用B760/Z790 4 DIMM主板,2根海力士Adie 16GB或者Mdie 24GB上7200很简单。并且选择低价位的6xxx频率的ADIE就可以,这相比XMP 7800/8000这种高频内存要便宜不少,基本没有什么额外花费。 但上7600+以上频率对于内存体质和处理器内存控制器体质就有一定的要求。
虽然低频Adie也有不少可以手动超频到8000,但往往需要更高的电压,更高的电压也意味着更大的功耗和发热,如果再缩小参数的话的就很难真正稳定。因此类似我这次测试使用的HOF OC Lab幻迹S D5-8000 16GBx2内存采用特挑Adie的原生XMP 8000内存,在高频压制小参的情况需要的电压更低,这样发热更小,还是有更好的稳定性。
如果是ROG STRIX Z790I GAMING/Z790 APEX Encore这样的2DIMM Z790就可以比较轻松的上8000,基本对CPU的内存控制器体质没有上面要求,当然如果你想尝试冲击下8400甚至更高,当那还是需要特挑的处理器和内存,就如本次评测用到的影驰HOF OC Lab幻迹S D5-8000 16GBx2内存。
tRFC/tREFI这样的小参,对于延迟和游戏性能影响很大,但优化tRFC/tREFI后内存的温度提升,温度又会反过来影响稳定性,因此对于追求极限内存性能而压低小参的玩家,最好还是给内存配备类似乔思伯(JONSBO)NF-1 内存散热器这样的带有风扇的的主动散热器。大多内存的马甲更多是美观和保护PCB的作用,对于降温的效果并不明显。
24GB mdie相比16GB Adie容量大一半,而价格也没贵多少,电压更低并且更为容易上高频(因此24GB 8000是不限量供应,而16GB 8000反而需要特挑限量),24GB Mdie对于内存控制器体质要求更低,但参数压不下去,可玩性其实是不如Adie的,因此比较合适那些有一定容量需求,但也想兼顾频率的玩家。
需要大容量的可以选择购买Adie 32GB x 2或者MDie 48GB x 2,XMP频率一般再6400-6800,愿意折腾手动可以到7200+,但这样仅仅合适对于容量有刚需的生产力环境,低频+高延迟使得游戏性能明显不如DDR4,因此并不合适游戏玩家。
DDR5不建议使用4条,4根Adie 16GBx4一般可以上6400,不如两根32GB或者48GBx2,而且稳定性也不好保证,4根32GB/48GB基本只能 4000/4800,性能完全不如DDR4,甚至有可能直接点不亮,完全不推荐。
虽然现在美光/三星也都更新了自己的颗粒,但相比海力士还是不可燃垃圾,性能还不如D4,也没便宜多少,完全没有购买价值。
散热选择建议
14600K相比13600K功耗略高一点,在Z790上默认电压功耗(150-160W)比较低,基本5-6热管高端单塔或者入门双塔就压得住,比如利民的PA120se或者雅浚的B6。而在B760上由于默认电压比较高,180W功耗也偏高,并且目前无法降压,需要好点的双塔或者240/360水冷才压得住。
13700K默认250-260W,但在降压到220W之后顶级的双塔就压得住,但14700K随着核心频率和E-core数量的提升,功耗提升到280W水平,降压大概可以降到230W,这个功耗可以说是顶级双塔的极限,如果跑YC或者P95的话功耗更高,就不能完全压制在100度以内,但这样也不是不能用,略微降频对于性能影响很小。
如果希望能够完全镇压,还是需要360水冷起步,注重性价比的话我推荐瓦尔基里的A360/和即将上市的雅浚BA5,价格不贵,但基本可以满足14700K的散热需求,当然你如果有更高散热性能追求也可以参考下面i9的散热推荐。
之前13900K满载功耗在340W水平,降压到300W以下,类似ROG龙神3/雅浚GA5这样的高性能360还勉强压得住。虽然14900K频率就拉高了0.2GHz,但功耗爆炸到370W以上,降压以后也要350W,360 AIO这样的通常散热已经没有办法压住,需要高功率的分体式水甚至水冷机/压缩机才行,买高端水冷也只是尽可能提高性能释放水平。
当然上面说的400W是烤机或者是生产力情况,日常游戏CPU功耗并没那么夸张,如果你主要是游戏,对于散热也不用太过于焦虑,顶多就是在游戏加载解压或者编译shader时候温度爆炸风扇狂转而已。
总结和展望
14代Raptor Lake Refresh相比13代完全是牙膏,性能提升很小,这是 毫无疑问的。这样主要原因有三个方面:
首先从本次的测试就可以看出,AMD Zen 4虽然采用新5nm新工艺和全新平台,但实际效能相比Zen 3提升幅度并不算太大,Raptor-Lake性能依然有优势,再Refresh下就可以继续扩大领先优势,AMD再桌面端并不能给intel足够压力把牙膏挤出来,所以intel有恃无恐。
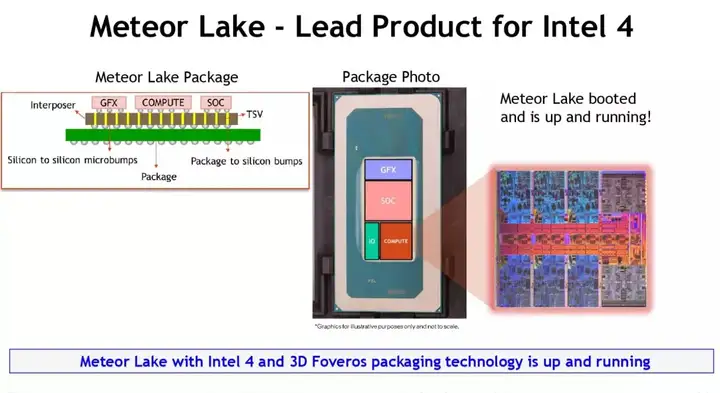
其次intel之前的计划是Raptor Lake-S后面更新Meteor Lake-S,但从目前的公开的消息看桌面端的Meteor Lake-S已经放弃,下代直接上Arrow Lake-S。Meteor Lake核心架构上只Raptor Lake的小改,在IPC上没明显提升。但最高规格只有6P+16E,并且采用的intel 4工艺是高密度库,主要为密度和中低频能效优化,高频上不去(目前MTL移动版频率最高才5.1 GHz),这样的工艺做移动平台没啥问题,但6大核+低频肯定是打不过现在的Raptor Lake Refresh,比11代Rocket Lake-S情况还糟糕,而Meteor Lake情况也跟原本的11代ice Lake类似,现在作为Foveros工艺试水只用来做移动端。
既然既定新品不靠谱,对手又不给力,那就只能继续牙膏。而且成熟工艺越到后期成本越低,利润越高,特别是再工艺架构都不更新的情况下,现在的Raptor Lake+Intel 7工艺对于intel来说完全是舒适区,自然能不动就不动。

而明年AMD将会在上半年推出新一代的Zen 5,Zen5虽然继续沿用Zen 4的接口和平台,但从泄露的PPT上看,Zen 5的IPC相比Zen 4有10-15%提升。不出意外明年的Zen 5在效能上将会再次领先于intel的Raptor Lake。
intel方面的应对则是明年下半年推出采用20A工艺的Arrow Lake,这将抛弃传统的FinFet首次运用GAA,晶体管密度/能效/性能都将大幅提升,架构上也有比较大的变化。
- Intel Raptor Lake 125W (PL1/PL2/PL4) 24 Core SKU - 125W / 253W / 420W
- Intel Arrow Lake 125W (PL1/PL2/PL4) 24 Core SKU - 125W / 177W / 333W
现在的消息是ARL的PL2/PL4相比RPL下降了30%/20%,因此ARL的能效表现十分值得期待。

其实早些时候有传言20A翻车,Arrow-Lake将采用台积电N3工艺,而后续将直接跳到18A,但在上月的Intel Innovation 2023的intel CEO Pat Gelsinger展示了Arrow Lake的20A测试芯片晶圆无疑是狠狠的打了这以谣言的脸。并且明年这个时候台积电还是N3E和N3P这样的传统FinFet,这将是intel多年之后在制程方面首次实现堆台积电的反超。(明年三星3nm也是GAA,看现在A17 Pro的N3表现,不出意外的话台积电明年估计又要变成三家最弱的台漏电)