腾讯文档在线表格卡顿指标探索之路
作者:被删
还记得当年刚来文档的时候,有人问我要不要接卡顿,又有人跟我说别接啊很难的这个,页面都卡没了不好定位。
去年机缘巧合,卡顿这个事情又到我头上了,同事调侃说性能这个事情接手的都跑路了。
但问题不大,咱没事不惹事,来事不怕事,遇事能抗事,是只顶顶好的开发吗喽。
像腾讯文档这样的大型前端应用,面临的卡顿问题比常规前端页面要频繁得多。但卡顿本身难以监测,即使检测到卡顿的发生,也常常难以快速定位,更别提说想要了解大盘的用户真实体验。
需求产生了,便总会要研究解决方案的。本文记录了腾讯文档在线表格的卡顿体系搭建过程,包括卡顿检测、卡顿定位、卡顿指标、大盘数据搭建等内容。
卡顿的定义
Google 的 RAIL 模型提出:100 毫秒内完成由用户输入发起的转换,可以让用户感觉互动是瞬时完成的。
**为确保在 100 毫秒内获得可见响应,RAIL 的准则是在 50 毫秒内处理用户输入事件。**但对于在线表格这样的复杂应用,别说 50ms 了,超过 1s 的代码执行也比比皆是,尤其大文档的大数据操作下还有不少超过 10s 的代码执行耗时。
根据 Jakob Nielsen’s work on response time limits 提出的三个阈值,1 秒大概是用户思想流保持不间断的极限,即使用户会注意到延迟。因此,作为卡顿的指标来说,相比于 100ms,我们取了 1 秒作为卡顿的分界线。
我们在项目中定义了两种卡顿指标(后续会介绍原因):
- 技术侧卡顿:代码长任务,JS 执行耗时超过 1 秒。
- 用户侧卡顿:交互响应耗时,用户操作同步/异步阻塞。
一、技术侧卡顿指标
检测代码执行超过 1 秒的方法有很多,这里简单概括下。
1. requestAnimationFrame
我们的项目中,卡顿使用window.requestAnimationFrame来进行检测,检测原理很简单:假设我们认为页面中存在超过特定时间(比如 1s)的长耗时任务即存在明显卡顿,则我们可以判断两次window.requestAnimationFrame执行间超过阈值时间,则认为是发生了卡顿。
class HeartbeatMonitor {
// 上一次心跳的时间
private preHeartBeatTime: number;
private checkNextTick() {
this.preHeartBeatTime = Date.now();
requestAnimationFrame(() => {
const currentTime = Date.now();
// 取出执行耗时
let timeDistance = currentTime - this.preHeartBeatTime;
// 超过 1s 则认为是卡顿了
if (timeDistance > 1000) {
// 注:dispatchEvent 为伪代码,具体可自行实现
// 对外抛事件表示发生了卡顿
this.dispatchEvent("jank");
} else {
// 对外抛事件表示为普通心跳
this.dispatchEvent("heartbeat");
}
// 继续下一次检测
this.checkNextTick();
});
}
}
2. PerformanceObserver
除了requestAnimationFrame之外,之前在《有趣的 PerformanceObserver》一文中,有详细介绍常见的前端性能指标都可以使用PerformanceObserver来实现,包括:
- Long Tasks API 方案:Long Task API 定义了任何连续不间断的且主 UI 线程繁忙 50 毫秒及以上的时间区间(存在兼容性问题)
- PerformanceEventTiming:用户交互事件时间信息,可自行计算执行耗时(存在兼容性问题)
- web-vital 开源库: 提供了常见前端指标的获取(CSI、LCP、FID、INP 等)
其中,谷歌的 web-vital 开源库提供了很多开箱可用的前端指标,但我们的目标不只是要一个数值而已,我们还希望能直观看到卡顿产生的有关信息,包括卡顿产生的位置、所属模块等等。
我们需要一整套有效的检测方案。
但技术没有银弹,对于复杂项目来说,想要“自动化”、“可视化埋点”、“无痕埋点”、“无侵入性”的方案多少有些自欺欺人。代码量太大,函数执行调用链路长到无法自动化,想要真正有用有效能看的数据,最实在的还是花点时间定位,然后老老实实埋点。
因此,当requestAnimationFrame检测出卡顿时,我们可以通过埋点的方式,来分析具体产生卡顿的位置。
3. FPS 和 TBT
除了 JS 执行耗时,我们还可以增加其他指标进行辅助。 卡顿指标是用户使用流畅度的一种,同样体现流畅度的,我们还可以使用 FPS 和 TBT 来从不同角度体现用户使用流畅度:
- Total Blocking Time (TBT) (opens new window):总阻塞时间,测量 FCP 和 TTI 之间的总时间,在此期间,主线程处于屏蔽状态的时间够长,足以阻止输入响应。可以使用
PerformanceObserver+Long Tasks API来计算得到 - FPS:画面每秒传输帧数,即在每秒内能够渲染多少帧画面。可以使用
requestAnimationFrame计算得到
卡顿埋点方案
检测页面是否发生了卡顿的方案很多也很简单,但如果想要定位哪里产生了卡顿,才是卡顿监控的最大难题。
一般来说,我们定位卡顿问题,都是使用 Performance 面板来查产生卡顿的代码位置,如下图:
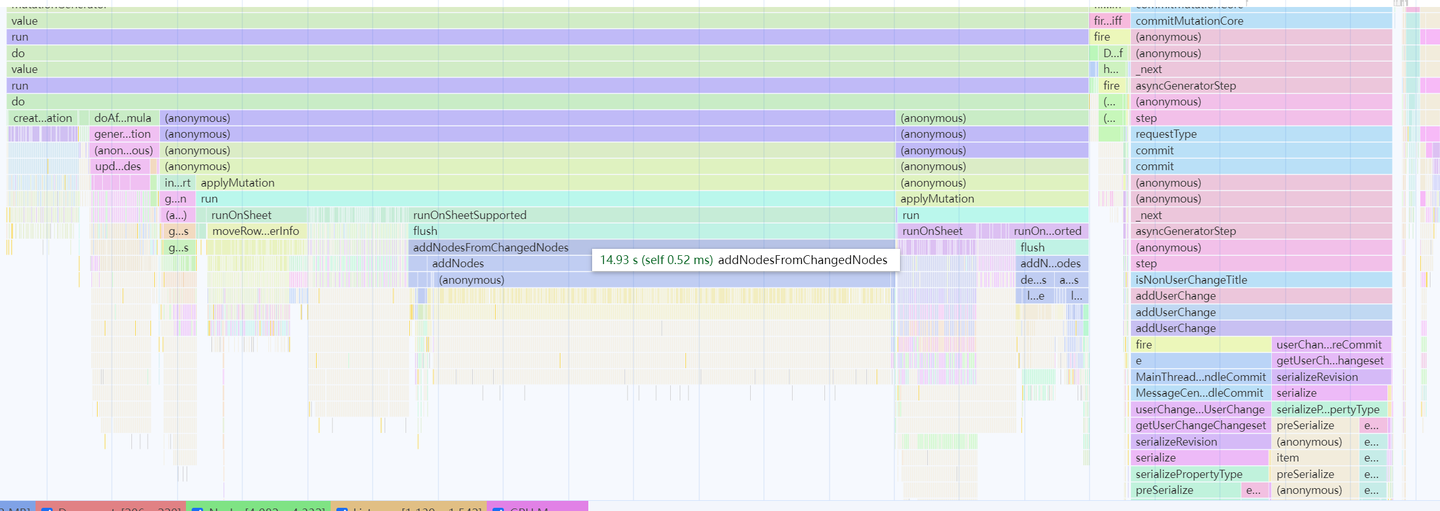
火焰图可以一眼看出其中执行耗时较长的部分,可以根据具体的代码识别出所属的模块信息。当然,如果希望解决这个长耗时的问题,则还需要结合 Bottom-Up 面板来定位耗时较长的函数方法,并研究解决方案。
但对于检测卡顿产生的位置来说,我们则可以简单地通过几个函数执行的入口进行计算:

图中,假设我们在代码执行过程中打了埋点(1、2、3),我们在卡顿产生的时候则可以拿到:
- 第一段函数方法的执行耗时:埋点 2 时间戳减去埋点 1 时间戳
- 第二段函数方法的执行耗时:埋点 3 时间戳减去埋点 2 时间戳
从而拿到可参考的卡顿位置来做数据上报,获取大盘的用户数据。该方案的弊端是:卡顿上报是否准确,依赖于埋点是否完整和准确。调试和补充埋点的过程费时又费力,目前基本上是基于收到的用户反馈,在已知定位过的卡顿流程上补齐了埋点。
至此,我们简单理一下卡顿的埋点检测方案:
- 检测两次
window.requestAnimationFrame之间是否产生卡顿(超过 1s),如果不超过则认为没有产生卡顿,并清空已有埋点。 - 如果产生了卡顿(> 1s),则将埋点取出来,并取出本次执行流程中超过 1s 的埋点,如果没有的话,则计算获取耗时最长的位置。
- 将产生卡顿的位置进行上报。
流程图就懒得画了,可以直接看伪代码:
class JankMonitor {
// 心跳 SDK
private heartBeatMonitor: HeartbeatMonitor;
// 卡顿链路堆栈
private jankLogStack: IJankLog[] = [];
constructor() {
// 初始化并绑定事件
this.heartBeatMonitor = new HeartbeatMonitor();
// PS:此处 addEventListener 为伪代码,可自行实现一个事件转发器
this.heartBeatMonitor.addEventListener("jank", this.handleJank);
this.heartBeatMonitor.addEventListener("heartbeat", this.handleHeartBeat);
// 可以初始化的时候就启动
this.heartBeatMonitor.start();
}
log(logPosition: { module: string; action: string }) {
this.jankLogStack.push({
...logPosition,
logTime: Date.now(),
});
}
/**
* 处理卡顿
*/
private handleJank() {
const jankPosition = this.calculateJankPosition();
// 拿到卡顿位置后,可以进行上报
// PS: reportJank 为伪代码,可以根据项目情况自行实现
reportJank(jankPosition);
// 打印异常
console.error("产生了卡顿,位置信息为:", jankPosition);
// 上报结束后,则需要清空堆栈,继续监听
this.jankLogStack = [];
}
/**
* 处理心跳
*/
private handleHeartBeat() {
// 心跳的时候,可以将堆栈清空,因为正常心跳发生意味着没有卡顿,此时堆栈内信息可以移除
this.jankLogStack = [];
// 清空后,添加心跳信息,方便计算耗时
this.jankLogStack.push({
module: "jank",
action: "heartbeat",
logTime: Date.now(),
});
}
private calculateJankPosition() {
// 记录产生卡顿的位置
let jankPosition;
// 记录最大耗时
let maxCostTime = 0;
// 遍历堆栈,计算每一步耗时
// 第一个信息为心跳信息,可从第二个开始算起
for (let i = 1; i < this.jankLogStack.length; i++) {
// 上个位置
const previousPosition = this.jankLogStack[i - 1];
// 当前位置
const currentPosition = this.jankLogStack[i];
// 链路耗时
const costTime = currentPosition.logTime - previousPosition.logTime;
// 可以将链路打出来,方便定位
console.log(
`${previousPosition.module}-${previousPosition.action} -> ${currentPosition.module}-${currentPosition.action}, 耗时 ${costTime} ms`
);
// 找出最大耗时和最大位置
if (costTime > maxCostTime) {
maxCostTime = costTime;
jankPosition = {
...currentPosition,
costTime,
};
}
}
return jankPosition;
}
}
只要埋点位置准确的话,就可以实现卡顿链路基本上与 Performance 一致:

通过这样的链路日志,我们可以很清晰低地看到具体产生卡顿的位置,并且掌握整个卡顿的调用链路。
除此之外,我们还可以拿到执行耗时超过 1 秒的位置,或是卡顿过程中耗时最长的代码位置,从而生成产生卡顿的具体模块的大盘数据,供后续性能优化的工作来参考。
二、用户侧卡顿指标
现在,我们已经可以检测并定位这样的卡顿:代码执行耗时超过 1s 的长任务。产生卡顿时,我们可以进行卡顿指标以及日志的上报,通过捞取对应日志的方式,来定位一些卡顿的产生原因。
但实际上,该方案难以准确命中“用户侧卡顿”的场景,原因包括:
- 超过 1s 的任务执行时,用户未必在进行表格操作,未感受到“卡顿”。
- 对用户来说,使用表格各个过程中的卡顿阈值是不一致的,比如:
- 表格打开过程中,会习惯性地等待,此时卡顿阈值会稍微高一些
- 表格加载完成后,对各种功能的操作响应更敏感,希望能快速响应操作
这也是我们后来新增了用户侧卡顿指标的原因。但如何判断用户交互后产生了卡顿呢?我们可以拆分成以下情况:
- **同步阻塞:指用户交互后,执行同步长耗时任务产生卡顿。**举例说明就是,用户点击的同时页面就卡住了,因为这时候我们的 JS 代码监听到事件后就直接进行计算逻辑了。
- 异步阻塞:指执行异步逻辑的时候产生卡顿。在项目中我们很多异步计算的逻辑,比如用户操作后,函数计算可能会在 Worker/Webassembly 中进行,计算完成后返回结果,主线程处理结果的时候同样可能产生卡顿,用户的体验是点击后页面动了一下,然后再卡住。
我们来分别看看两种场景的卡顿如何识别。
1. 交互后同步卡顿
对于同步阻塞的场景比较好解,我们可以在监听到用户交互时进行耗时计算:
window.addEventListener("click", () => {
const startTime = new Date().getTime();
requestAnimationFrame(() => {
const duringTime = new Date().getTime() - startTime;
// 交互后超过 1s 才响应
if (duringTime > 1000) {
// 则判断为卡顿
}
}, 0);
});
我们可以对关注的用户事件进行监听和计算,比如click/touchend/scroll等。除此之外,我们还可以基于PerformanceEventTiming来实现:
new PerformanceObserver((list) => {
list.getEntries().forEach((entry) => {
// 完整耗时
const duration = entry.duration;
// 输入延迟(处理事件之前)
const delay = entry.processingStart - entry.startTime;
// 同步事件处理时间
const eventHandlerTime = entry.processingEnd - entry.processingStart;
console.log(`Total duration: ${duration}`);
console.log(`Event delay: ${delay}`);
console.log(`Event handler duration: ${eventHandlerTime}`);
});
}).observe({ type: "event" });
而Event Timing API中包括的用户交互事件几乎是很全的,包括 INP 指标也是可以基于此方式来计算。
2. 异步逻辑卡顿
对于异步逻辑导致的卡顿,由于卡顿发生在用户交互后,难以通过代码直接发现。
我们可以从另外一个角度分析,即当页面交互发生卡顿时,用户常常会在页面中进行操作,来确认页面是否无响应。
因此,我们可以通过这样的代码判断:
let clickCount = 0;
let hasClick = false;
window.addEventListener("click", () => {
clickCount++;
if (hasClick) return;
hasClick = true;
requestAnimationFrame(() => {
// 卡顿过程中发生了连续点击操作
if (clickCount > 3) {
// 则判断为卡顿
}
// 清空数据
clickCount = 0;
hasClick = false;
}, 0);
});
原理很简单,requestAnimationFrame会在浏览器的每一帧中被执行到,如图:
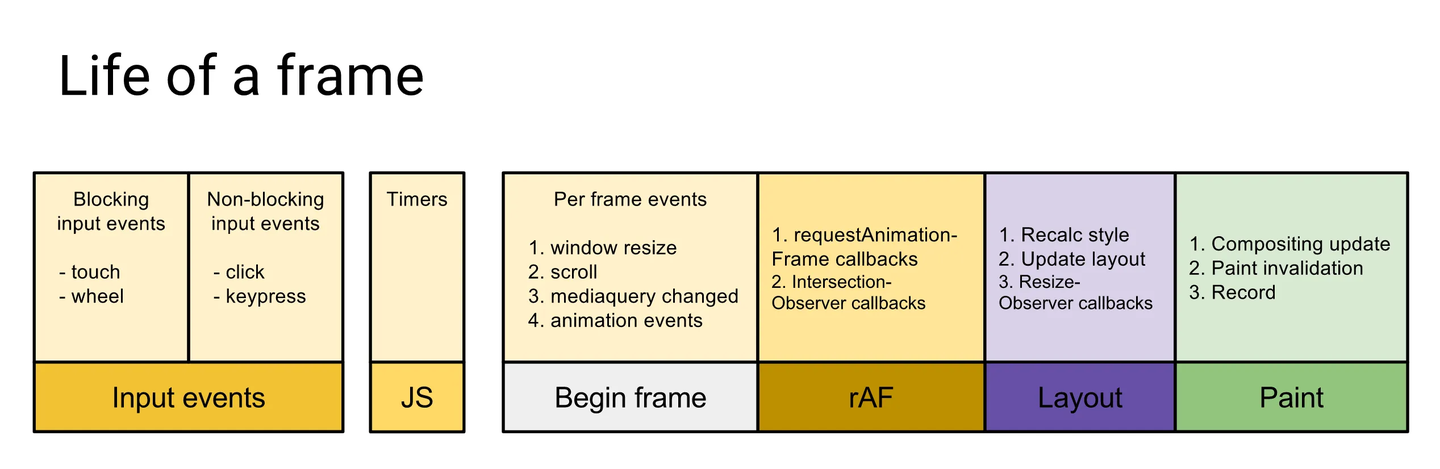
每一帧的浏览器渲染过程顺序为:
- 用户事件。
- 一个宏任务。
- 队列中全部微任务。
requestAnimationFrame。- 浏览器重排/重绘。
requestIdleCallback。
正常的页面使用过程,用户交互的每次事件都会在一次渲染流程中执行requestAnimationFrame,不会产生计数累计。
而当页面卡顿时(主线程繁忙),用户会下意识地多次操作页面,这些事件便会被堆积等到下一帧渲染过程,此时会先执行事件中的计数,再到requestAnimationFrame时,该计数便会大于 1。
用户侧卡顿指标定义
到这里,我们介绍了交互后同步卡顿和异步卡顿的两种检测手段。
我们会将以下情况作为一次卡顿的产生,并且做卡顿次数的上报:
- 用户交互后,同步卡顿超过 1s
- 检测到一帧的浏览器渲染过程中,用户连续点击操作超过 3 次
基于用户体感卡顿的指标,我们可以打造更有效的卡顿日志上报。
更有效卡顿日志捞取
由于表格项目过于复杂,再加上大数据的操作和计算,我们面临的问题是:超过 1s 的长任务太多,实际上捞出来的日志 90% 都被上述问题占据,很难发现新的问题。
因此,我们可能得从用户角度来分析卡顿问题,更准确地命中用户痛点,主动发现并解决。
在整理用户反馈时发现,相比于表格加载过程中偶尔一两秒的卡顿,更让他们难以接受的问题有频繁出现卡顿、某个操作卡顿耗时过长、某个较频繁的操作必现卡顿等。
前面提到,让用户更难接受的问题包括:频繁出现卡顿、某个操作卡顿耗时过长、某个较频繁的操作必现卡顿等。因此,我们会在以下场景发生的时候,将数据以及日志同时进行上报:
- 频繁卡顿:10s 内产生卡顿次数 > 5。
- 较大卡顿:检测到某段代码执行超过 5s/10s。
- 反复卡顿:检测到卡顿埋点中卡顿(超过 1s)的相同埋点多次产生(相同的卡顿埋点次数 > 5)。
三、更多维度的卡顿信息
基于用户的使用习惯,在表格打开加载过程中更多会进行滚动操作,而在认为表格加载完成之后,才会进行编辑操作。
这个使用习惯是否是准确的呢?结合我们的大盘数据来看,约 70% 以上的用户会在用户加载完成后才会进行编辑。
我们可以将卡顿产生的时机与应用的生命周期结合起来,来查看各个生命周期中的卡顿情况,比如:
- 数据加载情况:加载了多少片数据、表格是否完整加载
- APP 生命周期:首屏数据加载、只读模块加载、可编模块加载等
- 模块加载情况:各个 Feature 模块的加载情况、懒加载模块的加载情况等
有了更多维度的数据,我们就可以更全面地分析大盘用户的卡顿是在哪个生命周期中产生的,是否跟代码和数据未完全加载等情况有关系。
大盘卡顿指标看板搭建
我们常说的大盘数据便是真实用户监控(Real User Monitoring,RUM),可以有效反应真实用户的整体使用情况。
我们卡顿大盘数据的搭建,同时使用了前面介绍的技术侧卡顿指标和用户侧卡顿指标。
为什么要有两种卡顿指标呢?因为他们是相辅相成的:
- 考虑 JS 执行耗时的卡顿检测机制,由于卡顿产生时用户未必在进行交互,因此难以真实反应用户的真实体验
- 考虑用户侧的卡顿检测机制,当检测到卡顿产生时(
requestAnimationFrame后判断)相关的卡顿埋点已经被清除了,无法获取卡顿产生的位置
基于两种卡顿指标,我们分别可以建立不同角度的卡顿大盘数据:
- 技术侧卡顿数据:结合卡顿埋点方案,我们可以搭建基于不同模块维度的卡顿情况,优先解决卡顿较多的问题。
- 用户侧卡顿数据:该指标可以用于监控大盘用户的真实卡顿率。
1. 各模块卡顿指标看板
由于具体卡顿的模块位置依赖于埋点数据,因此该看板主要数据来源于技术侧卡顿指标。
我们可以通过该看板分析各个模块的卡顿数据,考虑各个性能问题的处理优先级,同时通过看板观察优化前后的卡顿效果。
2. 用户使用卡顿率
前面说过,通过 JS 执行判断卡顿的方式不一定与用户真实的使用体验完全一致。
我们在上线用户侧卡顿指标之后,很长一段时间内都没有发现两个指标是否不一致。
正当困惑新增的用户侧卡顿指标是否多此一举时,发现有一次迭代中带了一个渲染模块导致卡顿的 BUG,此时两个指标的不一致(数据已脱敏):
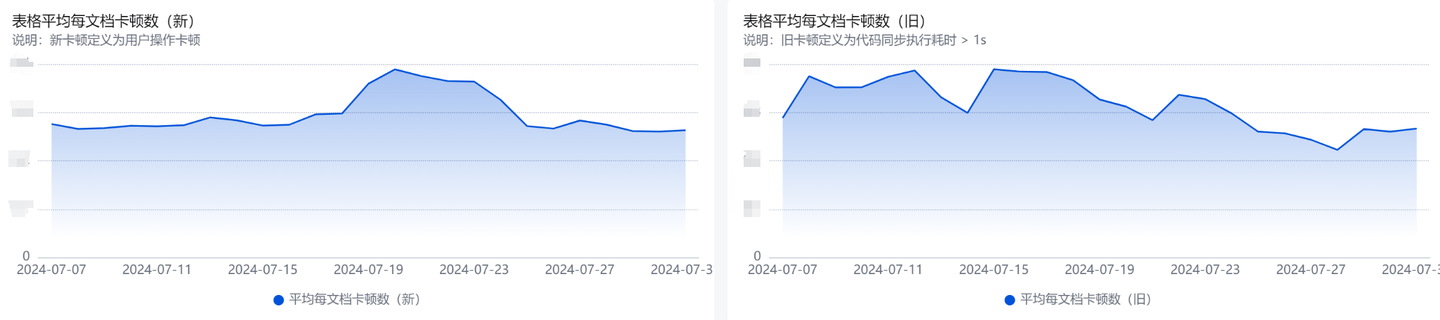
用户侧卡顿的曲线与 JS 执行卡顿的曲线不一致,原因如下:
该周期中虽然渲染模块卡顿 BUG 上涨了,但是由于相同迭代中模块加载卡顿 BUG 下降了,导致总的卡顿数并没有太大变化,JS 执行卡顿总数并没有明显不一致(反而有些下降了)。
但是,我们看看用户侧卡顿的数据曲线便能发现,该曲线能真实反馈用户使用过程的卡顿,因为随着用户侧卡顿率的上涨,那几天我们收到了不少的用户卡顿反馈,与曲线涨跌相吻合。
而对于同步和异步两个卡顿曲线,我们还可以分开观察(数据已脱敏):
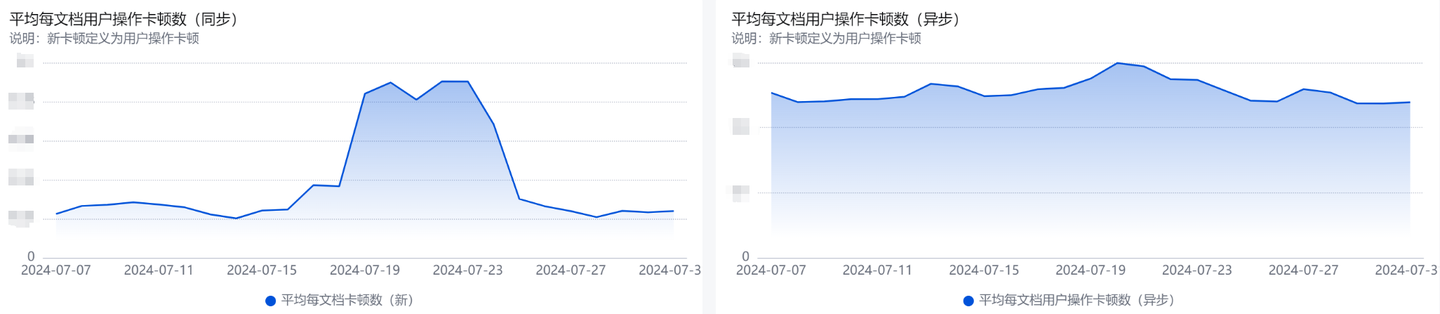
虽然两个曲线都有符合周期的上涨,但同步交互卡顿的指标有十分明显的上涨。这是因为该卡顿 BUG 导致操作后同步卡顿的场景占比更高。
至此,用户侧卡顿的指标测试阶段结束,相比于 JS 代码执行卡顿,该指标更能体现用户的真实感受。
3. 更多卡顿指标建设
除了各模块卡顿的情况,我们还可以搭建更多的卡顿指标,包括:
- 整表使用过程中,是否曾经产生过卡顿
- 表格使用过程中,共产生了多少次卡顿
- FPS 和 TBT 情况
我们还可以将这些指标结合更多维度的信息来搭建需要的信息,比如:
- 卡顿产生与表格大小(单元格数量)的关系
- 卡顿产生阶段:与生命周期的关系
通过这些数据的整理,我们可以建立更多维度的卡顿数据看板。
实验室监控指标搭建
由于大盘数据的数据体系十分庞大,一些特定场景或是特征表格的特点操作数据会被大盘稀释,难以及时发现问题。
表格开发过程中也不少遇到这样的问题,发布前以及灰度过程中开发自测发现卡顿时,大盘指标数据并无任何影响。比如:
- 某分支上 A 需求引入性能问题,该过程无有效监控。
- B 需求灰度过程,大表加载卡顿定位,此时整表可编辑的大盘指标并没有发现异常
- C 分支行高问题导致某个表格加载慢,特征表格加载缓慢,大盘数据也不受影响。
这些场景下,实验室数据(Synthetic Monitoring,SYN)或许比真实用户大盘数据更能监控到性能问题,因此我们会将指标分为两种:
- 真实数据指标:监控大盘用户数据,识别关键链路(打开/可用性)性能情况
- 实验室数据指标:监控特征表格及特征操作性能数据,稳定的实验室环境更容易及时发现性能问题
真实数据指标往往由大盘数据进行展示和监控,通常采用平均值(也可参考 PSI 改用 75 百分位数据,但大盘数据来说影响不大),可以大体反馈表格整体加载的情况。
相比真实用户数据,实验室数据无法真实反应表格在不同的设备、网络环境下的使用情况。但实验室数据也有其优势:
- 环境比较稳定,可直观反应细微的性能问题变化
- 可针对特征表格和特征操作做定制化性能测试,并提供相关性能数据的变化
- 可进行可能影响表格流畅度的指标数据获取,比如平均滚动帧率、表格加载平均内存占用等
- 可每日基于主干分支代码进行测试,在发布前提前发现问题
因此,实验室指标监控的事项,我们也正在搭建试验中。
结束语
作为一名开发,为什么要关注自己的业务数据呢?
因为我们经常需要在开发过程中进行取舍:使用缓存换速度、牺牲性能换内存等,在庞大的模块加载数量中选择先后。要怎么进行决策呢?相比于拍脑袋,有数据支撑的决策想必更有参考性,更具备说服力。
时间很宝贵,认认真真思考再来打磨,或许比先上线再优化更好些呢?