用DDD(领域驱动设计)和ADT(代数数据类型)提升代码质量
很多开发者都有一个迷思,认为项目里的代码质量和可维护性的持续下降,主要根源在于时间紧迫、需求变动频繁。如果产品需求更加明确,并给予足够的开发时间,开发团队可以长期保证代码质量和可维护性。
今天介绍的 DDD(领域驱动设计) 和 ADT(代数数据类型) 的模型,给出了另一部分的答案:代码质量持续下降,开发团队也要负主要责任。
如果没有采用更合理的开发模型,项目的代码质量将随着时间和复杂度的增加而急剧下降。再明确的产品需求,再多的开发时间,也很难阻止代码库的腐坏。
由于 DDD 和 ADT 都是很大的主题。很难在一篇技术文章中充分展开。因此,本文主要是简要地介绍它们之间的关系以及背后的思想,希望能够带给大家一些启发。感兴趣的同学,后续可以查阅更深入的材料。
主要内容分成以下几个部分:
- 代码质量的评估方式
- DDD 的概念与定义
- ADT 的概念的定义
- 案例:用 DDD + ADT 做数据建模
- 案例:用 DDD + ADT 做流程建模
- 总结
1、代码质量的评估方式

不管做哪种提升和优化,最关键的起始步骤总是寻找衡量的标准和方法。提升代码质量也不例外。
1.1、代码质量的评估标准
- 可拓展性 (Extensibility)
- 可维护性 (Maintainability)
- 可读性 (Readability)
- 可测试性 (Testability)
- etc.
上述指标是在一个相对宏观的层面评估代码,偏向定性指标。
给定两段代码,开发可以判断出哪一个可拓展性更好,但具体好多少,却不容易有一致的判断。特别是可读性这个指标,非常依赖开发者的经验和主观偏好。
有一些定量指标,比如一些 Lint 规则、循环引用检测等,对提升代码质量也有帮助。但这类定量指标的不足之处在于,它们在一个非常微观的层面做代码评估,并不关心代码要解决的问题是什么。
这类定量指标,容易失效甚至带来反效果。对处理具体问题的帮助也有限,主要服务于统一代码风格、约束写法、规避常见反模式。
我们希望有一种评估标准,既能在宏观定性层面帮助我们考虑问题,又能在微观定量层面帮助我们解决问题。
1.2、几种代码质量的提升方法
- SOLID Principles
- Clean Code Principles
- Design Patterns
- Low Coupling, High Cohesion
- etc.
有很多编程原则可以提升代码质量,其中最著名的两个或许是 SOLID 和设计模式 (Design Patterns),它们已经出现至少二三十年,在今天依然被开发者们津津乐道。
单一职责、开闭原则、接口分离原则、观察者模式、订阅模式、解释器模式、装饰器模式、低耦合、高内聚…… 这些词汇在程序员群体里耳熟能详,历久弥新。
不过:
- 有些开发者认为编程语言已经发展出了很多新特性,很多问题已经变了,原始的设计模式已经不适用于现在的情况。
- 很多开发者发现,严格地遵从和推广这些编程原则,反而让代码更加难以理解、难以维护。
大家发现了编程原则背后的认知偏差——相关性不等于因果。
从高质量的代码中提炼的特征,跟代码质量之间有一定的相关性,但不意味着是因果关系:高质量代码都有某些特征,不意味着有某些特征的代码就是高质量的代码。
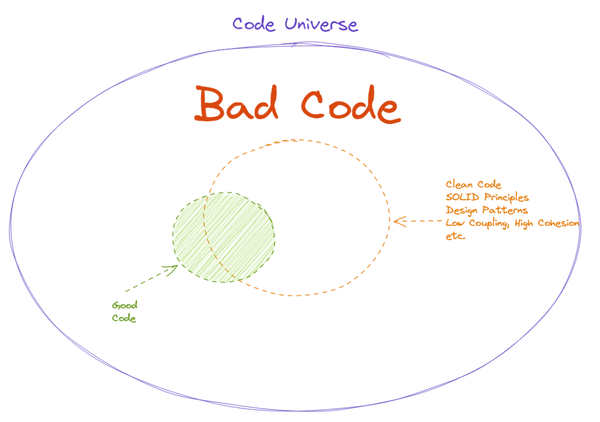
如上图所示,假设最大的圈是整个代码宇宙,里面的小绿圈是优质代码,绿圈之外则是低质量代码,黄圈则是符合 SOLID 等编程原则的代码。
我们可以看到,在这种关系中:
- 优质代码大部分具备 SOLID 等编程原则的特征(所以我们能从中提炼出 SOLID 特征)
- 但还有更多符合 SOLID 等特征的代码是低质量代码
- 有一小部分代码不符合 SOLID 特征,但也是优质代码
因此,盲目地在代码库里推广某种代码特征,往往会带来反效果。
1.3、当前代码指南的不足之处
目前的代码质量评估模型和代码指南,仍有以下几个不足之处:
- Subjective,依赖开发者主观经验
- Unclear,表述模糊,不够清晰
- Hindsight,对已写就的代码做事后评估,对写代码本身缺乏建设性指导
- Imprecise,不够精确,不够准确
- External,围绕代码表面的形式,忽视问题的本质特征,或者假设问题已经被解决
- etc.
与上面的不足相对的,我们可能想要的是:
- Objective,更加客观的,所有理性的开发者都有一致的认知
- Clear,表述清晰明确
- Insight,在写代码之前或写代码之时就能帮助洞察问题
- Precise,精确的代码评估标准
- Internal,围绕问题本质出发,不仅仅是代码的编写形式
- etc.
优雅的代码,不只是某种写法或者编程技巧,而是更深入地认识问题的本质后,所带来的副产品。
因此,代码怎么写,怎么写出高质量的代码,离不开提高对问题的理解水平。
编写高质量代码的指导模型,不能只关注代码怎么写的这一阶段,还需要有怎么认识问题的前置阶段。
2、DDD 的概念与定义
DDD(领域驱动设计)是 2003 年开始流行的一种开发模式,它的含义非常广。
领域驱动设计,不只是关注代码怎么写,更关注写代码之前的活动,比如产研流程和协作。
偏向写代码的 DDD,叫战术型 DDD;偏向产研流程和协作的 DDD,叫战略性 DDD。但它们的核心是一致的,后面我们会展开讨论。在此之前,让我们看看,朴素的产研模式。
2.1、朴素产研模型:需求驱动设计
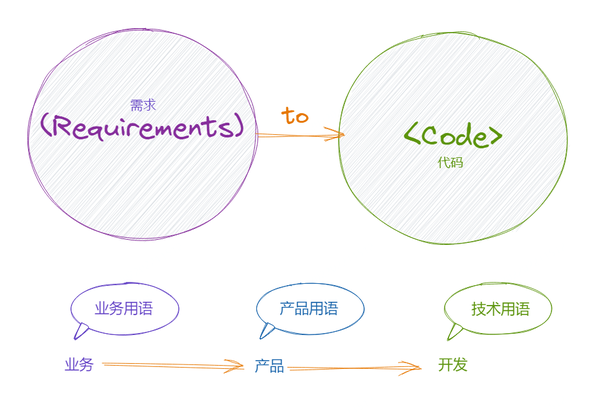
我们可以把这种模式称之为——需求驱动设计。
它的一般过程是,产品经理跟业务同事们沟通以及做市场调研分析,挖掘出产品需求,并制作成产品需求文档(PRD),然后开发根据 PRD 中的需求描述,提供代码实现。
在这种模式中,业务们有自己的业务用语,产品们也有自己的产品用语,开发工程师有自己的技术用语。它们之间有一定的关联,但并不足够紧密和强烈。
不会有人要求开发写代码时一定要用业务用语里的名词和概念。
从领域驱动设计的角度看,这个模式的问题就在于,不像一个团队,而是三个团队。
开发之间主要通过技术用语交流,消费的是上游产品用语的材料。开发很难确定自己接到的需求,是不是业务真正的需求,自己理解的逻辑,跟业务同事理解的是不是一样的。
在这种情况下,开发会强烈希望需求是尽可能真实的、明确的、稳定的。开发会很反感上游交付的是不确定的需求,代码频繁修改。
当遇到跟产品难以通过沟通达成共识的时候,开发会想要直接跟业务沟通,了解业务的一手需求。
在需求驱动设计的模式里,需求的生命周期很短,基本上需求发布上线不久之后,它们就被遗弃了。很少有产品团队能够始终维护完整的产品文档,跟线上的功能一一对应。往往在产品经理换人之后,需要通过读代码来反推产品逻辑。
这里问题就来了,代码是在技术用语的上下文里编写的,它们其实不容易反映产品里的概念,更加不用说业务概念了。
2.2、领域驱动设计的核心思想与关键过程
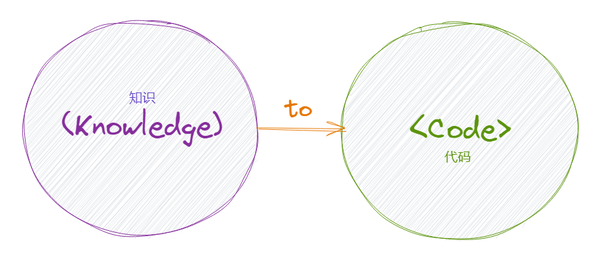
领域驱动设计的产研模型里,所凸显的重点是——知识。
如果说,需求是关于 How、要怎么做的,知识就是关于 What 和 Why 的,是什么,为什么。
知识和需求,也不冲突。需求就来自知识。
我们也可以把领域驱动设计,叫做——知识驱动开发。它强调的是,从领域知识到代码实现的过程。
不管是战术型 DDD,还是战略性 DDD,或者其它 DDD 的方面,都围绕知识驱动开发这个核心思想展开。把握住了核心,不容易被 DDD 里诸多复杂概念所迷惑。
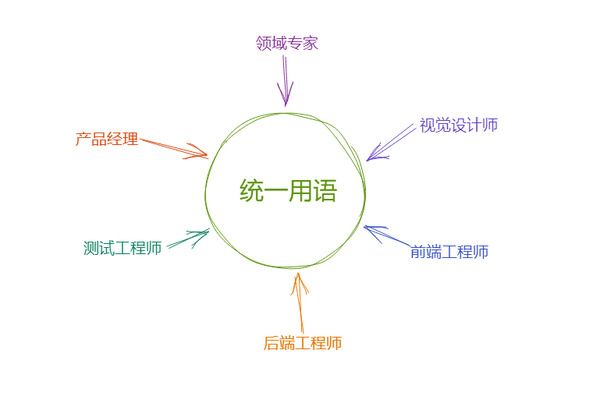
领域驱动设计的关键过程,是解决团队中不同岗位和角色之间,交流语言不统一的问题。
上图中的领域专家,大部分情况下指业务人员。但也不尽然如此,DDD 里的领域专家,不是一个岗位,而是一个角色。在特定领域里更专业、懂得更多、更权威,他就成了领域专家的角色。
通过构建团队统一用语,开发可以更为确定产品需求是真需求,自己理解的逻辑,跟领域专家或业务同事们的理解是一致的。因为大家都用同一套词汇,相同的定义,彼此有共识基础。
领域驱动设计和需求驱动设计的差异,可以从它们的会议形式上管中窥豹。

需求驱动设计的会议,通常是产品经理将已完稿的 PRD 进行讲解,前置的知识提取、梳理和定义等阶段,大体已经成形。

而领域驱动设计的会议,有所不同。如上图是一种被称之为事件风暴 (Event Storming) 的会议模式。领域专家、开发工程师等多个角色共同在一块长条白板上,基于时间轴和事件进行领域知识的表达和建构。
在这个过程中,业务领域里的实体、事件、流程、关系等诸多概念被提出、定义和明确,在场所有人都对此有共识。每一次事件风暴会议形成的词汇和术语,都作为下一次会议或者工作交流中的统一用语和语料。
2.3、小结
- 高质量的代码来自对问题的正确认知,很难在不理解问题的基础上优雅地解决问题
- 代码的写法、风格、模式等手段,建立在正确的认知基础上才能达到最佳的效果
- 忽视提高对问题的认知水平,盲目地运用代码技巧、设计模式,往往让代码更糟糕
- DDD 的核心思想是,以领域专家为核心,建立统一用语,确保知识和需求的可靠传递
3、ADT 的概念的定义
采用领域驱动设计的战略部分,可以优化团队协作模式,确保从知识到代码的过程中,知识部分是基于良好定义的共识所得到的,需求因而更有概率是真实需求。
而领域驱动设计的战术部分,则是反过来:从代码到知识。
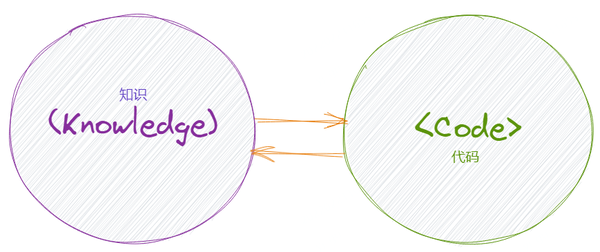
简单地说,DDD 要求代码中必须使用 “团队统一用语” 里的词汇和概念。
代码应当忠诚地反映领域知识。代码里的变量名、方法名以及核心逻辑,应当反映领域知识里的定义。代码编写不是随意的,而是每一个掌握了领域知识的开发者,都能写出大体一致的代码,而非五花八门的多样性实现。
如果说需求驱动设计,要求代码满足产品需求的外延定义。即在输入 / 输出的功能层面满足产品需求。
那么领域驱动设计,要求代码满足领域知识的内涵定义。不仅在输入 / 输出的黑盒层面满足功能要求,在代码细节的白盒层面也满足领域知识的定义。
这要求我们必须知道,如何把领域知识翻译成代码实现。
代数数据类型 (ADT, Algebraic Data Types) 是支撑上述需求的关键编程特性。
3.1、领域和领域知识的定义
首先我们需要精确定义什么是领域(Domain),什么是领域知识 (Domain Knowledge)。
- Domain(领域) 是一系列关联问题构成的集合
- Domain Knowledge(领域知识)是一系列关联问题涉及的所有真命题 (true proposition) 的集合
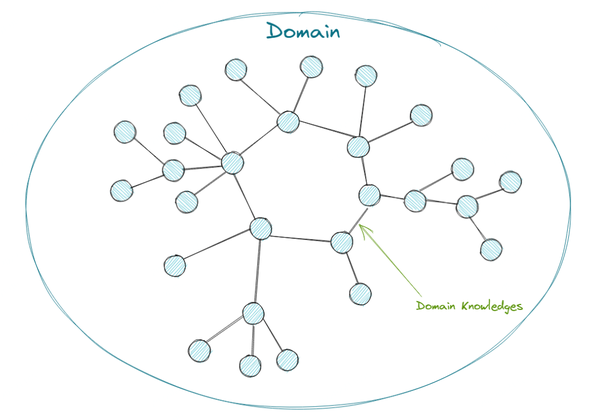
所有领域,都由一些关键概念节点构成,领域知识则是这些概念节点之间的关系的定义,表达为逻辑上的真命题。
作为命题的领域知识,在产品需求里被表述为一系列领域规则 / 业务规则。
产研团队常说的业务逻辑,可以被翻译为更严格的数学逻辑的表达形式。
3.2、柯里 - 霍华德同构
用代码表达领域知识的原理——柯里 - 霍华德同构 (Curry–Howard isomorphism)。
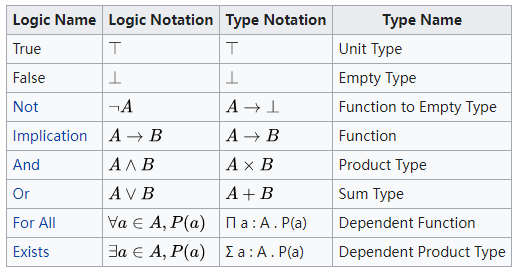
- 命题即类型,证明即程序 (Propositions as Types, Proofs as Programs)
- Type-Driven Development(类型驱动开发),用类型去表达领域知识 (领域里的真命题)
- 符合类型的所有值,都是该类型所表征的命题的证明 (Witness)
- 真命题:至少有一个值的类型
- 假命题:没有任何值的类型
柯里 - 霍华德同构,给出了将命题翻译为类型的方式,它提供了将领域知识翻译成代码实现的通用方式。
特别是对应着 And 关系的 Product Type,和对应着 Or 关系的 Sum Type,它们两个构成了代数数据类型 (ADT)。
后续我们将演示,如何用 Product Type 和 Sum Type 做数据建模和流程建模,跟领域知识 / 业务规则一一对应起来。
值得一提的是,在柯里 - 霍华德同构中,真命题和假命题,并不是对应着 Boolean Type 的 true 和 false。而是类型所允许的值的数量 (size),0 个值为假命题,至少 1 个值为真命题。
也就是说,所有能运行的代码在这个意义上都是真命题,抛错等行为才意味着碰到程序的假命题。
3.3、Bug 的定义和高质量代码的判别标准
通过柯里 - 霍华德同构,Bug 的定义,以及高质量的代码的判别标准,也有了更清晰的陈述。
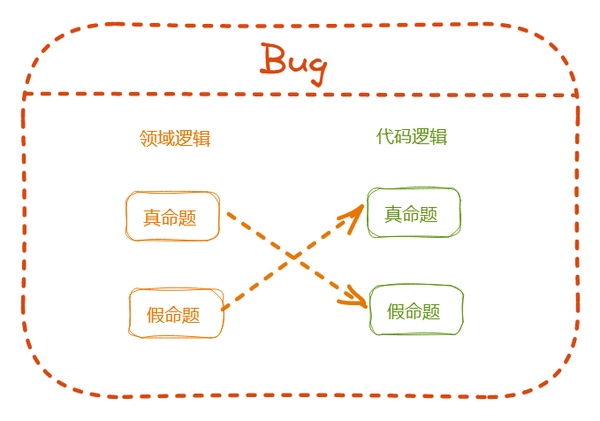
在将领域逻辑翻译成代码逻辑的过程中,如果发生匹配错乱,领域里的命题跟代码里的命题不一致,Bug 就发生了。
- 领域里的真命题 (领域知识),代码里却是假命题 (Error/Crash/Halt)
- 领域里的假命题,代码里却是真命题 (Illegal-States/Unexpected-Behaviors)
所有能跑的程序都是程序意义上的真命题,但不意味着是业务意义上的真命题,这种不匹配被称之为非法状态(Illegal-States)、非法操作(Illegal-Operations)或不预期的行为 (Unexpected Behaviors),是应当被避免的。
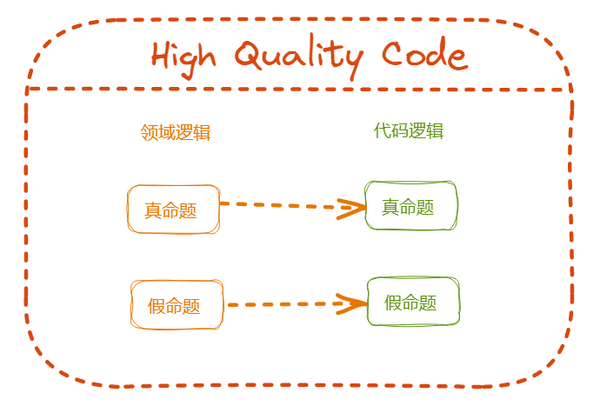
所谓的高质量代码,与 Bug 的定义相反,领域里的命题跟代码里的命题一致。
- 领域里的真命题 (领域知识),代码里也是真命题
- 领域里的假命题,代码里也是假命题
这意味着,代码里运行着的程序和数据,需要都是有业务意义的。更少的非法状态、非法操作和不预期的行为。
3.4、类型论 (Type Theory) 的基础知识
In type theory, every term has a type. A term and its type are often written together as "term : type".
类型论和集合论在某些方面很类似,它们都是对合集 (collection) 的不同建模。在这里,合集 (collection) 是指一堆事物的聚合。
在类型论中,事物被称之为项 (term),它有且只有一个类型 (type)。而类型 (type),可以有零到任意多个项 (term)。其中一些典型的类型,列举如下:
- 空类型 (Empty type),0 个项;
- 单元类型 (Unit type), 1 个项;
- 布尔类型 (Boolean type), 两个项,true 或者 false;
- 自然数类型 (Natural Numbers type),无限多个项,从 0 开始。
- etc.
如上,我们例举了一些基础类型,它们的 term 的数量也标记了出来,跟集合论里的元素数量类似。
3.5、代数数据类型 (Algebraic Data Types)
In type theory, an algebraic data type is a kind of composite type, i.e., a type formed by combining other types.
所谓的代数数据类型 (ADT),指的是多个类型组合成新的类型的方式,这些组合方式拥有一些代数特征。
由前面的柯里 - 霍华德同构,我们知道,逻辑的 Or,对应的类型是 Sum type,表达的是互斥的、或的关系。而逻辑的 And,对应的类型是 Product type,表达的是并存的,与的关系。
其中,Sum 含义是相加,Product 是指相乘,描述的是 Sum type 和 Product type 的项的数量,跟它的组成部分的类型的项数量的关系。
- Sum type: size(A | B) = size(A) + size(B)
- Product type: size(A & B) = size(A) * size(B)
如上,size(..) 函数可以获取特定 type 所允许的 term 的数量。
那么,Sum type 对应的就是加法,因为 A 和 B 在这里是 “或” 的关系,是互斥的,不会一起出现,所以要么 A,要么 B。那所有可能性就是 A 的可能数量,加上 B 的可能数量。
// sum types
type Value = string | number;
const a: Value = 'John';
const b: Value = 70;
而 Product type 对应的是乘法,因为 A 和 B 在这里是 “与” 的关系,是并存的,会一起出现,所以既有 A,也有 B。那就进入 A 和 B 的组合可能性,每一个 A 都能搭配所有 B,有 A 个 B,即 A * B。
// product types
type Person = { name: string; age: number };
// type Person = { name: string } & { age: number }
const person: Person = { name: 'John', age: 70 };
如上,对象的字段之间是 product type 关系。product type 不是具体的某个类型,而是一系列类型,只要它们背后的 size 关系是乘法相关的。同理,sum type 指的是那些背后的 size 关系是加法相关的类型。
只需要了解到目前的程度,代数数据类型 (ADT) 已经可以优化我们的代码质量了。接下来,我们来看看它在数据建模和流程建模上的应用。
4、案例:用 DDD + ADT 做数据建模
假设有以下用户信息的领域规则 (业务定义):
- 用户要么是已登录用户,要么是未登录用户(游客)
- 游客拥有随机的昵称
- 已登录用户拥有昵称、Email 信息
- Email 信息要么是已验证的 Email,要么是未验证的 Email
- 已验证的 Email 有验证时间戳
- 用户信息通过 Http API 获取
它们被描述为一组自然语言描述的规则,其实也可以提取出一些逻辑语言描述的命题。比如:
- 登录用户拥有昵称——true,真命题
- 未登录用户拥有 Email 信息——false,假命题
- 未验证的 Email 有时间戳——false,假命题
- etc
因此,领域知识未必是直白的逻辑语言,但它们总是可以提炼出逻辑命题,这些命题就是我们翻译到类型的指引。
4.1、常见的数据建模
type UserInfo = {
// 当用户未登录时,id 为空字符串
id: string;
// 当用户未登录时,name 为随机生成的昵称
name: string;
// 当用户未登录时,email 为空字符串
email: string;
// 用户是否登录
isLogin: boolean;
// 当邮箱未验证时,这个字段为 false
isEmailVerified: boolean;
// 当邮箱已验证时,这个字段为验证时间戳,否则为空字符串
emailVerifiedAt: string;
};
// Http API 获取用户信息
type JsonResponse = {
error?: string;
// 当 error 为空时,这个字段为用户信息
data?: UserInfo;
};
本案例中的用户信息的数据建模,其实非常简单,大部分开发者都习以为常,很容易写出像上面那种代码,并且不觉得有任何问题。代码简洁、清晰并且直观,注释完整。即便不能说是优质代码,起码是不坏的代码。
4.2、基于 DDD + ADT 的领域类型建模
采用 DDD + ADT 的模型,用户信息的类型大致如下:
type VerifiedEmailInfo = {
type: 'VerifiedEmailInfo';
email: string;
verifiedAt: string;
};
type UnverifiedEmailInfo = {
type: 'UnverifiedEmailInfo';
email: string;
};
type EmailInfo = VerifiedEmailInfo | UnverifiedEmailInfo;
type LoginUserInfo = {
type: 'LoginUserInfo';
id: string;
name: string;
emailInfo: EmailInfo;
};
type GuestUserInfo = {
type: 'GuestUserInfo';
name: string;
};
type UserInfo = LoginUserInfo | GuestUserInfo;
type ErrorResponse = {
type: 'ErrorResponse';
error: string;
};
type DataResponse = {
type: 'DataResponse';
data: UserInfo;
};
type JsonResponse = ErrorResponse | DataResponse;
我们一口气写了 9 个类型,看起来复杂了许多,更多的嵌套,更多的重复字段 (如 email, name 等),一行注释都没有,代码行数也翻倍了。
然而,上面的代码,更加符合业务规则的描述,更加准确地匹配了领域知识里的 And 和 Or 的关系。如果说它看起来不如第一种简单,那这个复杂度也是领域知识里自身的复杂度,更简单的定义某种意义上是——过度简化。
此外,代码的复杂度,跟代码的长度,不是必然关系。表面上的简单,和实质的简单,也不是一回事儿。
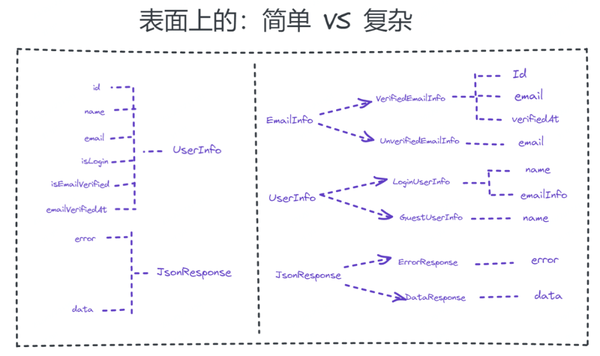
表面上,左侧拥有更少的嵌套,更少的字段,更少的类型,更简短的代码,在形式上无疑是比右侧的更简单的。
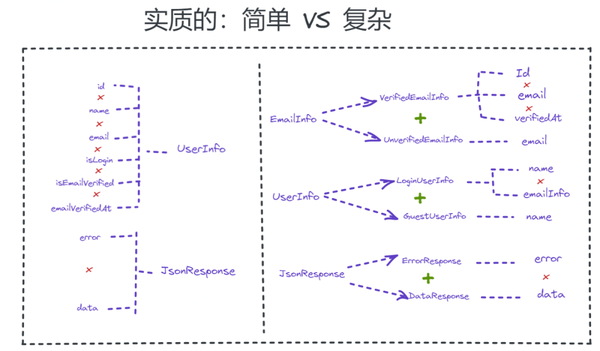
实际上,当我们把类型之间的关系标记出来时,我们发现,左侧其实拥有更多的乘法,而右侧则包含几个加法。多个乘法复杂度的类型,允许的 term 的可能性更多,size 更大。因此,左侧的 term size 大于右侧的。
4.3、非法状态对代码库的腐坏
当类型的命题空间,大于领域规则的命题空间,所多出来的部分,就是非法状态的空间。
非法状态将持续腐坏我们的代码库,从以下几个方面可见一斑。
1)非法状态鼓励错误的代码
const handleLoginUser = (userInfo: UserInfo) => {
// 直接访问 email,而没有先判断是否 isLogin
console.log('login user email', userInfo.email);
}
对象的字段之间是 product type 的并存关系,即便是未登录的用户,也有 email 字段,只是为空字符串。开发者需要主动的、自觉的记得判断是否登录,否则将产生错误隐患。
2)非法状态导致过度防御性编程,增加代码复杂度和代码量
const handleLoginUser = (userInfo: UserInfo) => {
// 防御性编程,判断是否已登录
if (!userInfo.isLogin) {
return;
}
console.log('login user email', userInfo.email);
}
const handleLoginUser1 = (userInfo: UserInfo) => {
// 防御性编程,判断是否已登录
if (!userInfo.isLogin) {
return;
}
console.log('login user email', userInfo.email);
}
在所有消费 UserInfo 的函数或者方法中,必须添加防御性逻辑,手动验证和排除非法状态,然后再消费数据。
也就是说,定义类型时所节省的复杂度,在类型消费的所有地方,都额外增加了防御性代码。数据的类型定义只有一处,但数据的消费却可以有很多处。相较之下,整体代码量更多,代码复杂度更高。
3)非法状态带来更多逻辑不同步
很多防御性判断,是在迭代过程中,一点点累积起来的。一开始往往没有收口到通用的函数里,它们重复地出现在多个消费数据的函数里。当需要更新某个防御性判断时,需要开发者记得在所有修改的地方,都改一遍。任何遗漏,都带来防御逻辑的不一致。
正因如此,Don't Repeat Yourself(DRP) 才作为一个最佳实践的指导原则被提出。在这个场景中,DRP 属于治标的做法,治本的做法则是从源头解决,用更精确的类型定义,减少不必要的防御性判断。
4)非法状态带来更差的性能
所有消费数据的函数和方法,都需要带上特定的防御性逻辑。尽管我们可以通过 DRP 原则,将重复的防御性逻辑,收口在一处。但它们仍需在各个消费函数中被调用。
这些消费函数彼此互相调用时,防御性逻辑将被重复执行。即便上一个函数已经调用过,下一个函数依然要进行防御。因为它无法判断是否会被独立的调用,它自身需要做好防御性逻辑的内聚。
因此,非法状态将带来更差的性能,数据验证工作在代码运行期间反反复复地被计算。
4.4、知识和代码同构的巨大收益
与非法状态相反,当代码里的类型更加忠实地反映领域知识,非法状态被减少或消除,它们难以被构造和传播。领域知识被编码到类型里,由 type-checker 进行约束。
从以下几个方面带来巨大收益:
1)拒绝错误的代码
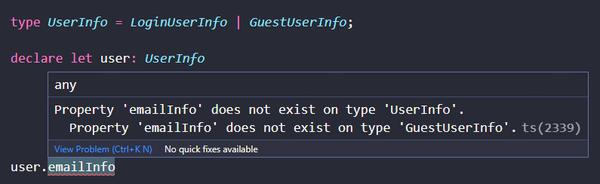
UserInfo 是一个 Sum type,有两种可能性 LoginUserInfo 和 GuestUserInfo。其中 GuestUserInfo 完全符合领域规则描述,只有一个 name 属性,而没有 emailInfo。
因此,user.email 无法通过类型检查。必须先证明 user 属于登录用户,才能访问 emailInfo 属性。
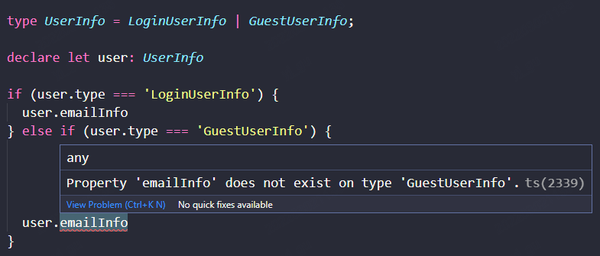
如上,当 user.type === LoginUserInfo 时,我们可以访问 emailInfo。而 user.type === GuestUserInfo 时,emailInfo 是不能访问的。
当我们正确地用 Sum type 表达领域知识里的 Or 的关系,我们更难写出错误的代码。
2)减少不必要的防御性逻辑及其运算开销
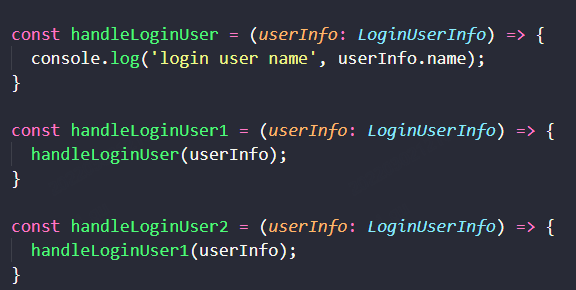
我们可以直接使用 Sum type 中,我们感兴趣的部分类型,构造我们的函数。如上所示,处理登录用户时,我们直接用 LoginUserInfo 类型,不必在函数内部防御是否登录。LoginUserInfo 存在,已经意味着已登录。
handleLoginUser1 调用了 handleLoginUser,handleLoginUser2 又调用了 handleLoginUser1。它们都没有额外的防御性逻辑代码。
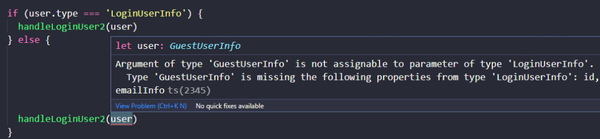
最外部调用 handleLoginUser2 时,才进行 sum type 分流判断。某种程度上,可以理解为,防御性代码被隔离到最外部的函数调用中。内部函数编写和组合时,代码更短、更安全、更少冗余开销。
3)代码更加容易阅读和维护
相比传统模式,领域知识被放到注释里,描述字段之间的协同关系的业务含义。DDD + ADT 的领域知识,就在类型里。
我们不必去猜测 user.isLogin, user.name, user.emailInfo 彼此之间的依赖关系,猜测有多少种可能的组合和场景。
type EmailInfo = VerifiedEmailInfo | UnverifiedEmailInfo;
type UserInfo = LoginUserInfo | GuestUserInfo;
type JsonResponse = ErrorResponse | DataResponse;
我们可以很直观地看到,两种就是两种,没有注释也能正确理解。不仅开发者理解,编译器也理解,并在每次消费 Sum type 时,约束开发者使其难以忘记和误解。
4.5、小结
- 领域知识里 Or 的关系,被曲解为 And,类型由加法复杂度,变成乘法复杂度
- 代码上能写出来的值 (value) 的数量(terms size),大于领域知识里的真命题的需求
- 代码里的真命题 (多出来的值),是领域里的假命题,它们成了非法状态(Illegal-States)
- 所有消费数据的地方,都需要做防御性判断,排除非法状态,否则就导致程序出现 BUG
- 系统的可维护性,跟非法状态在代码库里的泄漏程度成反比,泄漏越多,越难以维护和预测
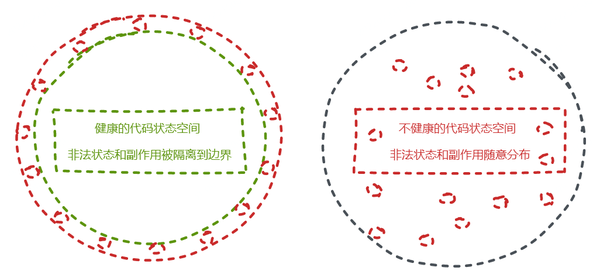
不健康的代码状态空间,非法状态和副作用随机分布。需要靠开发者付出更多额外的努力、写更多的注释、更多的防御性代码……,才能缓解代码腐坏的进程。然而,没有从源头解决问题,治标不治本,最终非法状态的蔓延,将很容易超出开发团队的掌控能力。特别是在人员流失和更替的过程中,领域知识在上一任开发者的脑海里,随着上一任的离去而丢失,在下一任开发者在脑海里重新建立领域知识的过程中,代码库可能已经加速腐坏。
通过 DDD + ADT,我们可以构建更健康的代码状态空间,用更精确和反映领域知识的类型,将非法状态的防御性判断逐层隔离到边界。让我们的核心代码变得简单可靠,领域知识被编码到类型里,由编译器的 type-checker 进行保证。即便开发者产生更替,编译器依然可以做出正确的提示。

通过 ADT 让非法状态无法被表示出来,从根源上优化代码质量。
5、案例:用 DDD + ADT 做流程建模
假设有以下领域规则:
- 用户发帖有 3 个阶段:草稿、审核、发布
- 草稿不能跳过审核直接发布
- 草稿可以提交审核
- 审核通过后可以发布
- 审核中的帖子不能修改
- 审核不通过退回草稿阶段
5.1、常见的流程建模
class Post {
constructor(
private isDraft: boolean,
private isReviewing: boolean,
private isPublished: boolean,
private content: string
) {}
edit(content: string) {
if (!this.isDraft) {
throw new Error('Post is not in draft stage');
}
this.content = content;
}
review() {
if (!this.isDraft) {
throw new Error('Post is not in draft stage');
}
this.isDraft = false;
this.isReviewing = true;
}
publish() {
if (!this.isReviewing) {
throw new Error('Post is not in reviewing stage');
}
this.isReviewing = false;
this.isPublished = true;
}
reject() {
if (!this.isReviewing) {
throw new Error('Post is not in reviewing stage');
}
this.isReviewing = false;
this.isDraft = true;
}
}
很多开发者很自然地编写出了上述代码逻辑。当调用 edit 方法编辑内容时,会先判断是否处于草稿阶段。每个相关方法内,都有状态验证。
问题在于,这种做法跟业务规则不是同构的。在业务规则中,编辑、审核、发布、退回等操作,不完全是并存的,而是随着草稿阶段、审核阶段、发布阶段而变化。但在 Post Class 中,edit, review, publish 和 reject 等方法并存,是 product type 的关系,没有忠实地体现领域知识。
因此,Post 的实例,存在很多非法操作 (Illegal Operations)。每一次方法调用,都需要调用者提前判断当前阶段,否则调用 edit 等方法将抛出错误。有意无意地忘记提前防御判断,Bug 将蔓延在代码库里。
当我们把各个方法里的防御性逻辑,从 throw error 改成静默,即只在符合条件时执行操作,否则什么都不做。那么,非法操作 (Illegal Operations) 将变成不预期行为(Unexpected Behaviors)。也就是说,所有方法调用,我们都不确定是否产生了效用,常常仍需额外的判断逻辑去确认。
非法操作一旦存在,不管以何种方式隐瞒不报,都会持续腐坏代码库。
5.2、基于 DDD + Class 的忠实流程建模
export class DraftPost {
constructor(private content: string) {}
edit(content: string) {
this.content = content;
}
review() {
return new ReviewingPost(this.content);
}
}
class ReviewingPost {
constructor(private content: string) {}
publish() {
return new PublishedPost(this.content);
}
reject() {
return new DraftPost(this.content);
}
approve() {
return new PublishedPost(this.content);
}
}
class PublishedPost {
constructor(private content: string) {}
getContent() {
return this.content;
}
}
如上所示,我们定义了三个 Class,分别表达三个阶段的 Post,对于每个阶段,所允许的方法都精确对应了领域规则。只有 DraftPost 拥有 edit 方法,是可编辑的;只有 ReviewingPost 拥有 publish 方法,是可发布的。
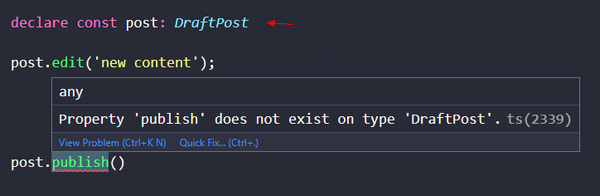
当我们获取到 DraftPost 实例,我们可以编辑它,但不能跳过审核直接 publish 发布它。
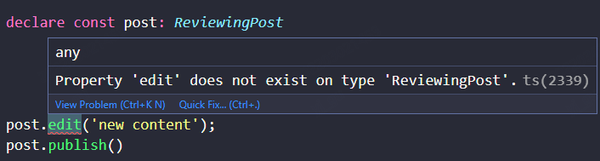
当我们获取到 ReviewingPost 的实例,我们可以发布它,但不能编辑它。
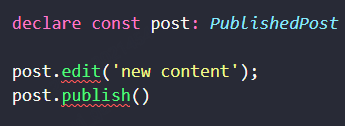
当我们获取到 PublishPost 的实例,我们既不能编辑,也不能重复发布它。

业务规则描述的流程,被编码到各个阶段的 Post 的方法调用的传递中,由编译器的 type-checker 去约束。
5.3、基于 DDD + ADT 的忠实流程建模
type DraftPost = {
type: 'DraftPost';
content: string;
}
type ReviewingPost = {
type: 'ReviewingPost';
content: string;
}
type PublishedPost = {
type: 'PublishedPost';
content: string;
}
const edit = (post: DraftPost, newContent: string): DraftPost => {
return {
...post,
content: newContent
}
}
const review = (post: DraftPost): ReviewingPost => {
return {
type: 'ReviewingPost',
content: post.content
}
}
const approve = (post: ReviewingPost): PublishedPost => {
return {
type: 'PublishedPost',
content: post.content
}
}
const reject = (post: ReviewingPost): DraftPost => {
return {
type: 'DraftPost',
content: post.content
}
}
除了用 Class 进行流程建模以外,面向数据的 ADT 也能做到,两者在流程建模的表达上是等价的。区别在于,数据和行为不再被放到一起,而是分开定义。但我们的 edit 只接受 DraftPost 数据,因而表达了只有草稿阶段才能编辑。review, approve, reject 等函数同理。
5.4、小结
- 将互斥的操作放到一起并存,关系从 Or 变成了 And,从加法复杂度变成乘法复杂度
- 代码上能调用的函数 / 方法的数量 (terms size),大于领域知识里的真命题的实际需求
- 代码里的真命题(多出来的方法调用),是领域里的假命题,它们成了非法操作 (Illegal-Operations)
- 所有调用方法的地方,都需要做防御性判断,排除非法调用,否则可能导致程序抛错和出 Bug
- 系统的可维护性,跟非法操作在代码库里的泄漏程度成反比,泄漏越多,越难以维护和预测

采用 DDD + ADT 的模型,让非法操作不能被调用,从根源上优化代码质量。
6、总结
不管是用户信息的数据建模,还是 Post 的流程建模,都是很常见的业务需求。它们的逻辑并不复杂,甚至在本文中还做了简化。即便如此,我们可以看到,大部分开发者下意识的代码实现,都包含着诸多隐患。存在很多难以消除的非法状态,以及难以管理的非法操作,不断地侵蚀着代码库。
可以想象,随着项目迭代,持续泄漏的非法状态和非法操作,将指数级地增加项目复杂度,让代码库难以理解、难以阅读和难以维护。犯错是被鼓励的,领域知识被写在不可运行和检查的注释中,代码的性能、逻辑一致性等诸多指标得不到保障。
而 DDD + ADT 模式,可以从根源上改变现状,优化代码库的整体质量。
- 运用领域驱动设计 (DDD),建立团队统一用语,获得可靠的领域知识,挖掘真实需求
- 运用代数数据类型 (ADT),对领域知识进行一比一建模,获得可靠的代码设计
- DDD+ADT:从知识中可以推导出代码,从代码中可以推导出知识,知识与代码的同构
- 核心技巧:多用 Sum type,少用 Product type,减少非法状态和非法操作的泄漏
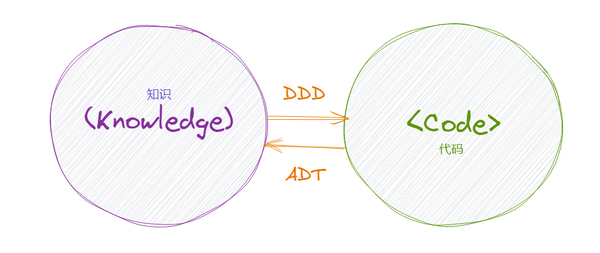
不仅从产品功能和行为的外延意义上,满足了业务需求;从代码的逻辑细节等内涵意义上,也满足了业务知识的要求。
让我们再回顾一下,我们想要的代码质量提升模型:
- Objective,更加客观的,所有理性的开发者都有一致的认知
- Clear,表述清晰明确
- Insight,在写代码之前或写代码之时就能帮助洞察问题
- Precise,精确的代码评估标准
- Internal,围绕问题本质出发,不仅仅是代码的编写形式
ADT+DDD 模式,更好地达到了上述目标。它们不仅仅是在代码工程领域的经验总结,背后其实有着一个世纪的学术积累与沉淀。
用 Phillip Wadle 的话来说,ADT 不是发明的,而是发现的。大部分开发者使用的编程语言及其特性,主要都是人类的发明。现在邀请大家来用人类所发现的语言特性。
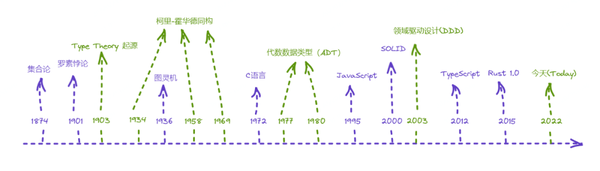
- 1874 年,康托尔建立集合论
- 1901 年,罗素发现集合论里的罗素悖论
- 1903 年,罗素用类型的思想,试图克服悖论,被视为类型论的起源之一
- 1934~1969 年,柯里和霍华德分别发现,类型论和逻辑演绎系统隐含的对应关系
- 1936 年,图灵发表图灵机模型
- 1972 年,C 语言诞生
- 1977~1980 年,代数数据类型 (ADT) 出现在函数式编程语言中
- 1995 年,前端的 JavaScript 语言诞生
- 2000 年,SOLID Principles 被归纳发表
- 2003 年,领域驱动设计(DDD)被提出
- 2012 年,前端的 TypeScript 语言诞生(本文的示例语言)
- 2015 年,Rust 语言 1.0 版本发布
- 2022 年,今天,我们的文章发表时间点。
每一行 DDD + ADT 的建模代码,背后都承载着历史的厚重、闪耀着人类理性的光辉。
https://zhuanlan.zhihu.com/p/475789952?utm_source=wechat_session&utm_medium=social&utm_oi=29435885518848&utm_campaign=shareopn