MySQL各种“Buffer”之Adaptive Hash Index
架构图
还是先来放一张MySQL的InnoDB体系架构图:(MySQL 5.7)
如图所示,在InnoDB体系架构图的内存结构中,还有一块区域(已经用红框标出)名为:Adaptive Hash Index,翻译成中文:自适应哈希索引,缩写:AHI。它是一个纯内存结构,今天就来盘它。
Adaptive Hash Index是什么
关于MySQL InnoDB哈希索引的传言
“江湖”上,流传着两种关于MySQL InnoDB哈希索引的传言。有一部分人说,InnoDB不支持哈希索引;有一部分人说,InnoDB支持哈希索引。那么到底谁说的对呢,其实两种说法都对!
- 说InnoDB不支持Hash Index一派的说辞:
先来回顾一下原来的student学生表的表结构:
CREATE TABLE `student` (
`student_id` int NOT NULL AUTO_INCREMENT COMMENT '学生编号',
`student_name` varchar(20) NOT NULL COMMENT '学生姓名',
`address` varchar(100) DEFAULT '北京市' COMMENT '家庭住址',
`extra` varchar(50) DEFAULT NULL COMMENT '额外信息',
`remark` tinytext COMMENT '备注',
PRIMARY KEY (`student_id`),
UNIQUE KEY `uniq_extra` (`extra`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '学生表';
然后,我们为address字段添加一个Hash Index,再顺便看一下创建完哈希索引后的表结构:
/* 给address字段创建Hash Index */
ALTER TABLE
`student`
ADD
INDEX `idx_address`(`address`) USING HASH;
/* 查看表结构 */
SHOW CREATE TABLE `student`;

从图中可以看到,我们的哈希索引创建成功了。但是,我们再执行一下SHOW INDEXES操作看一下:
SHOW INDEXES FROM `student`;

从图中的显示结果看,你会惊人的发现,刚创建的Hash Index,终归还是B+树Index。
所以,虽然MySQL支持创建哈希索引的语法,但是InnoDB用户无法手动正真创建出哈希索引,从这个角度来说,InnoDB确实不支持哈希索引;
- 说InnoDB支持Hash Index一派的说辞:
InnoDB会进行自调优(Self-tuning),如果判定建立Adaptive Hash Index,能够提升查询效率,InnoDB自己会在内存中建立相关哈希索引(所以这就是Adaptive——“自适应”的由来),不需要人工手动干预,InnoDB会根据所需自己创建自适应哈希索引。所以,从这个角度来说,InnoDB是支持哈希索引的。
Adaptive Hash Index概念
在MySQL运行的过程中,如果InnoDB发现,有很多寻路很长(比如B+树层数太多、回表次数多等情况)的SQL,并且有很多SQL会命中相同的页面(Page)的话,InnoDB会在自己的内存缓冲区(Buffer Pool)里,开辟一块区域,建立自适应哈希索引(Adaptive Hash Index,AHI),以加速查询。
官档地址:https://dev.mysql.com/doc/refman/5.7/en/innodb-adaptive-hash.html
涉及Adaptive Hash Index的参数
SHOW VARIABLES LIKE '%adaptive%';
- 参数: innodb_adaptive_hash_index
介绍:是否启用或禁用InnoDB 自适应哈希索引。默认情况下启用此变量。可以在线生效,无需重新启动服务器。禁用自适应哈希索引会立即清空哈希表。当哈希表被清空时,正常操作可以继续,并且执行使用哈希表的查询直接访问索引 B 树。当重新启用自适应散列索引时,在正常操作期间会再次填充散列表。
- 参数: innodb_adaptive_flushing
介绍:指定是否动态调整冲洗速度 脏页在 InnoDB 缓冲池中,根据工作负载。动态调整刷新率旨在避免I/O活动的爆发。默认情况下启用此设置。
- 参数: innodb_adaptive_flushing_lwm
介绍:定义表示启用自适应刷新的重做日志容量百分比的低水位线。(默认值10,最小值0,最大值70)
- 参数: innodb_adaptive_hash_index_parts
介绍:对自适应哈希索引搜索系统进行分区。每个索引都绑定到一个特定的分区,每个分区由一个单独的闩锁保护。在早期版本中,自适应哈希索引搜索系统由单个锁存器(btr_search_latch)保护,这可能会成为争用点。引入该innodb_adaptive_hash_index_parts选项后,搜索系统默认分为8个部分。最大设置为512。最小值为1。
- 参数: innodb_adaptive_max_sleep_delay
介绍:允许根据当前工作量InnoDB自动调整innodb_thread_sleep_delay up或down的值。任何非零值都可以自动、动态地调整innodb_thread_sleep_delay值,直至达到innodb_adaptive_max_sleep_delay选项中指定的最大值。该值表示微秒数。此选项在具有16个以上InnoDB线程的繁忙系统中很有用。(实际上,它对于具有数百或数千个同时连接的MySQL系统最有价值。)
小提示
相关参数解释了这么多,其实生产环境我们均采取默认值即可。
Adaptive Hash Index工作原理
准备工作
为了后面内容的顺利进行,我们对student学生表做了一些改造:
ALTER TABLE `student` DROP INDEX `uniq_extra`,DROP INDEX `idx_address`,ADD INDEX `idx_student_name` (`student_name`);
我们删除了之前创建的唯一索引uniq_extra,删除了并没有实际用处的“Hash”索引idx_address,为student_name学生姓名字段添加了一个普通二级索引。
ALTER TABLE `student` DROP COLUMN extra,DROP COLUMN remark;
同时把extra额外信息字段、remark备注字段DROP掉。
- 最后,我们看一下表结构和表中的数据:
/* 查看student表结构 */
SHOW CREATE TABLE `student`;
/* 查看student表数据 */
SELECT
*
FROM
student;
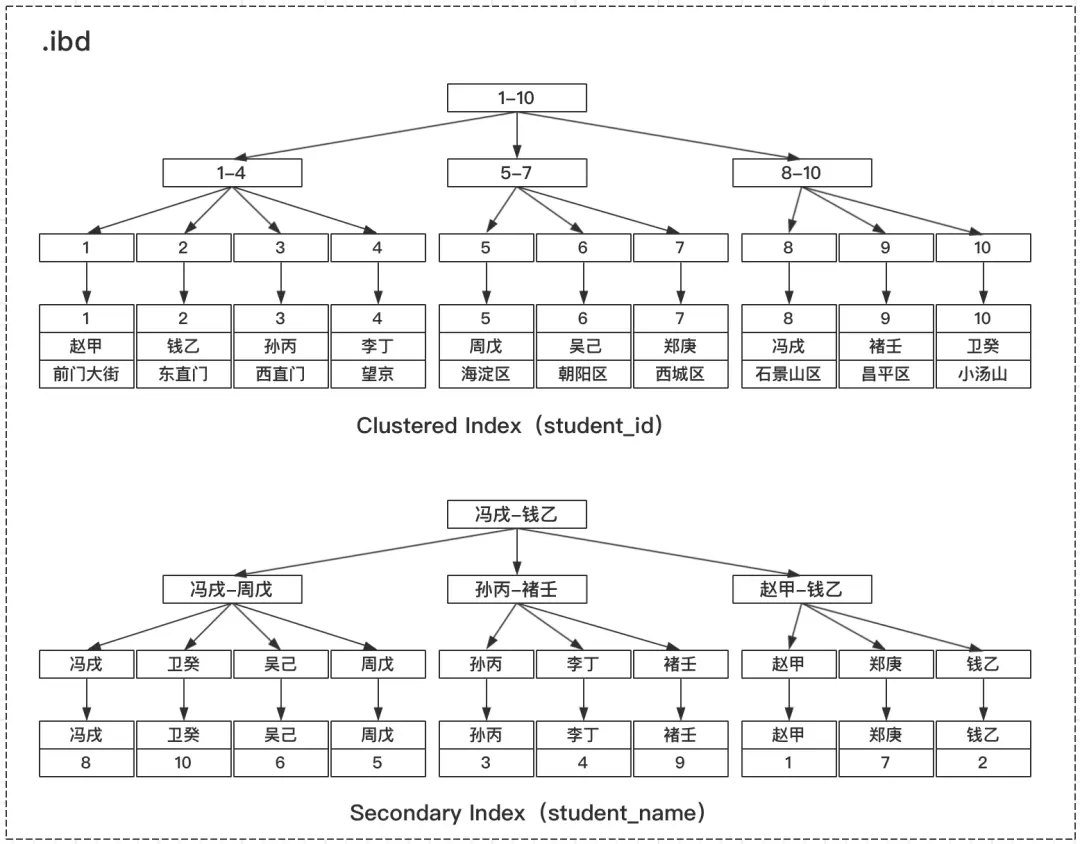
通过聚簇索引和普通索引访问记录的过程
聚簇索引访问记录过程
student学生表中的数据我们可以简易画一个B+树的结构图(真实的B+树结构要复杂的多,后期会开辟单独的文章详细讲解),如下所示:
InnoDB会在主键student_id上建立聚集索引(Clustered Index),Leaf叶子节点存储记录本身,在student_name上会建立普通索引(Secondary Index),叶子节点存储主键值(聚集索引就是数据的完整记录,普通索引也是单独的物理结构,两者均存放在.ibd文件中)。发起主键student_id查询时,能够通过聚集索引,直接定位到行记录。
SELECT * FROM `student` WHERE student_id = 6;
此时的过程如下图所示:
普通索引访问记录过程
SELECT * FROM `student` WHERE student_name = '褚壬';
通过普通索引查询记录时,和通过聚簇索引查询记录有所不同,分为两步:
- 步骤1:查询会先访问普通索引,定位到主键值9;
- 步骤2:再通过步骤1得到的主键值,回表到聚集索引上经过二次遍历定位到具体的完整记录。
通过Adaptive Hash Index访问记录的过程
从上面的流程图可以看出,不管是聚集索引还是普通索引,记录定位的寻路路径(Search Path)都很长。回到Adaptive Hash Index的概念上: 在MySQL运行的过程中**,如果InnoDB发现:**
-
有很多寻路很长(比如B+树层数太多、回表次数多等情况)的SQL;
-
有很多SQL会命中相同的页面(Page)。
InnoDB会在自己的内存缓冲区(Buffer Pool)里,开辟一块区域,建立自适应哈希索引(Adaptive Hash Index,AHI),以加速查询。
Adaptive Hash Index访问记录原理
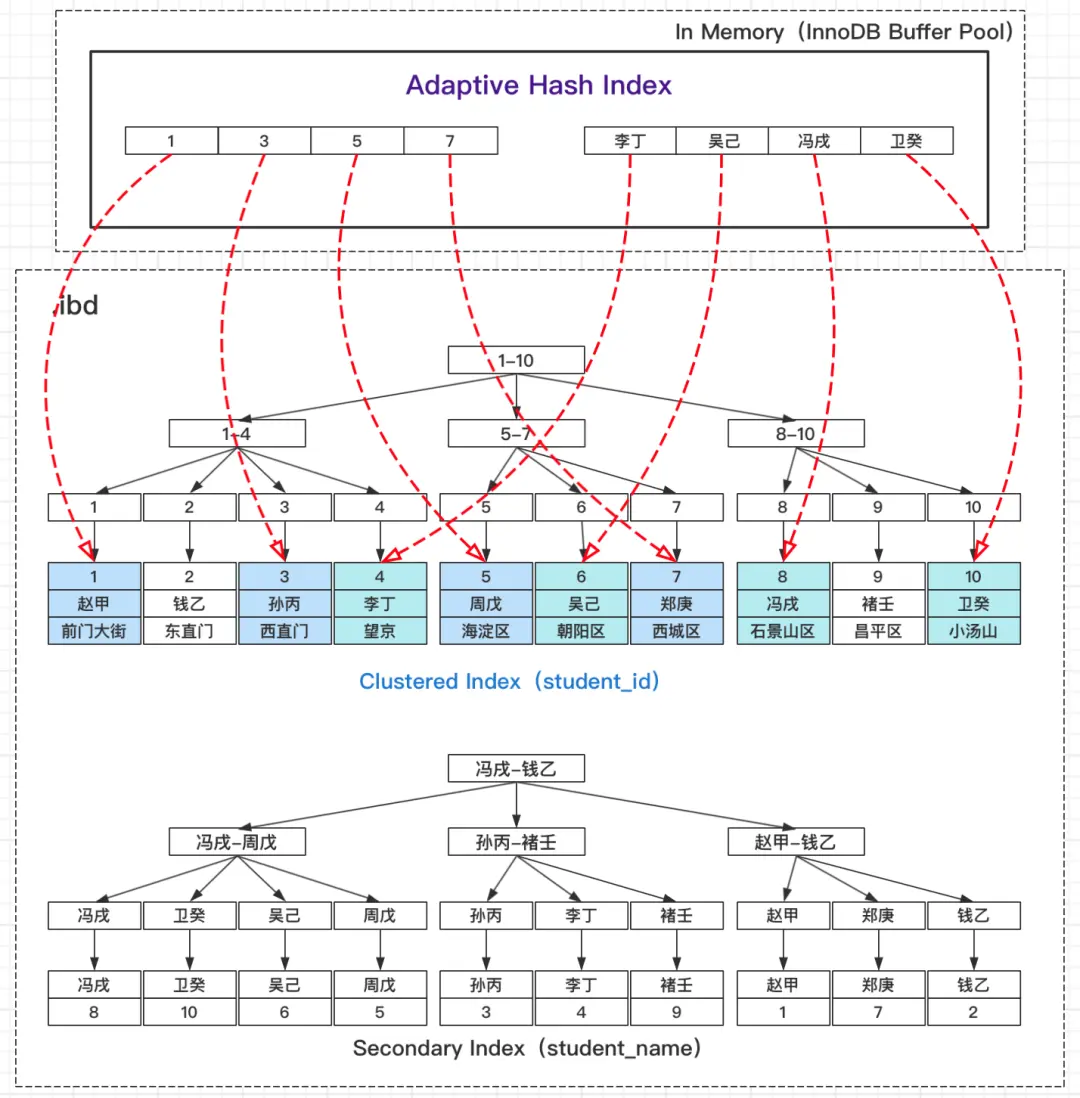
通过上面的流程图,我们可以得出以下结论:
-
MySQL InnoDB的Adaptive Hash Index,更像“索引的索引”,以此来缩短寻路路径(Search Path)。
-
**我们都知道,Hash数据结构都是包含键(Key)、值(Value)的,**在Adaptive Hash Index,Key就是经常访问到的索引键值,Value就是该索引键值匹配的完整记录所在页面(Page)的位置。
-
因为是MySQL InnoDB自己维护创建的,所以称之为“自适应”哈希索引,但系统也有误判的时候,也不能起到加速查询的效果。
知识补充
Adaptive Hash Index状态监控
SHOW ENGINE INNODB STATUS\G
(※ 注意:这是一段时间的结果。通过hash searches、non-hash searches计算AHI带来的收益以及成本,确定是否开启AHI)
Adaptive Hash Index使用场景
-
很多单行记录查询,比如用户登录系统时密码的校验。
-
索引范围查询,此时AHI可以快速定位首行记录。
-
所有记录内存能放得下,这时AHI往往是有效的。
-
当业务有大量LIKE或者JOIN,AHI的维护反而可能成为负担,降低系统效率,此时可以手动关闭AHI功能。
-
设置innodb_adaptive_hash_index_parts使用AHI分区/分片降低竞争提高并发,个别场景下,开了AHI后,可能导致spin_wait lock比较大,此时也可以关闭AHI功能。
Adaptive Hash Index注意事项
1、AHI目的:缓存索引中的热点数据,提高检索效率,时间复杂度O(1) VS O(N)的差异;
2、基于主键的搜索,几乎都是hash searches;
3、基于普通索引的搜索,大部分是non-hash searches,小部分是hash searches;
4、无序,没有树高,对热点Buffer Pool建立AHI,非持久化;
5、初始化为innodb_buffer_pool_size的1/64,会随着InnoDB Buffer Pool动态调整;
6、只支持等值查询(基于主键的等值查询AHI效果更好):
e.g.:
-
idx_a_b(a,b)
-
WHERE a=?
-
WHERE a=? and b=?
-
WHERE a IN (?)
-
WHERE a!=?
7、AHI很可能是部分长度索引,并非所有的查询都能有效果。
Adaptive Hash Index限制
1、只能用于等值比较,例如=、<=>、IN、AND等
2、无法用于排序
3、有冲突可能
4、MySQL自动(“自适应”)管理,人为无法干预。
小结
今天理论的知识不是很多,下面简单做一下总结:
- Adaptive Hash Index是内存结构,非持久化;**
- 设置innodb_adaptive_hash_index_parts,可以降低资源竞争提高并发;**
- 在Adaptive Hash Index,Key就是经常访问到的索引键值,Value就是该索引键值匹配的完整记录所在页面(Page)的位置;**
- Adaptive Hash Index只能用于等值比较,例如=、<=>、IN、AND等,无法用于排序;**
- Adaptive Hash Index是MySQL InnoDB自己维护创建的,人为无法干预。初始化为innodb_buffer_pool_size的1/64,会随着InnoDB Buffer Pool动态调整。**
- 基于主键的搜索,几乎都是hash searches;基于普通索引的搜索,大部分是non-hash searches,小部分是hash searches。**
今天主要讲解了MySQL InnoDB Adaptive Hash Index的工作原理,通过一些例子来说明整个过程,偏理论的知识,内容比较少也很好理解,大家理解记忆即可,面试中有被问到的可能